Chapter 4 Identification data
4.1 Identification data.frame
Let’s use the identification from from msdata:
## [1] "TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzid"The easiest way to read identification data in mzIdentML (often
abbreviated with mzid) into R is to read it with readPSMs()
function from the PSM
package. The function will parse the file and return a DataFrame.
## [1] 5802 35## [1] "sequence" "spectrumID"
## [3] "chargeState" "rank"
## [5] "passThreshold" "experimentalMassToCharge"
## [7] "calculatedMassToCharge" "peptideRef"
## [9] "modNum" "isDecoy"
## [11] "post" "pre"
## [13] "start" "end"
## [15] "DatabaseAccess" "DBseqLength"
## [17] "DatabaseSeq" "DatabaseDescription"
## [19] "scan.number.s." "acquisitionNum"
## [21] "spectrumFile" "idFile"
## [23] "MS.GF.RawScore" "MS.GF.DeNovoScore"
## [25] "MS.GF.SpecEValue" "MS.GF.EValue"
## [27] "MS.GF.QValue" "MS.GF.PepQValue"
## [29] "modPeptideRef" "modName"
## [31] "modMass" "modLocation"
## [33] "subOriginalResidue" "subReplacementResidue"
## [35] "subLocation"Exercise
Verify that this table contains 5802 matches for 5343 scans and 4938 peptides sequences.
## [1] 5802## [1] 5343## [1] 4938The PSM data are read as is, without and filtering. As we can see below, we still have all the hits from the forward and reverse (decoy) databases.
##
## FALSE TRUE
## 2906 28964.2 Keeping all matches
The data contains also contains multiple matches for several spectra. The table below shows the number of number of spectra that have 1, 2, … up to 5 matches.
##
## 1 2 3 4 5
## 4936 369 26 10 2Below, we can see how scan 1774 has 4 matches, all to sequence
RTRYQAEVR, which itself matches to 4 different proteins:
## DataFrame with 4 rows and 5 columns
## sequence spectrumID chargeState rank passThreshold
## <character> <character> <integer> <integer> <logical>
## 1 RTRYQAEVR controllerType=0 con.. 2 1 TRUE
## 2 RTRYQAEVR controllerType=0 con.. 2 1 TRUE
## 3 RTRYQAEVR controllerType=0 con.. 2 1 TRUE
## 4 RTRYQAEVR controllerType=0 con.. 2 1 TRUEIf the goal is to keep all the matches, but arranged by scan/spectrum,
one can reduce the DataFrame object by the spectrumID variable,
so that each scan correponds to a single row that still stores all
values5 The rownames aren’t needed here are are removed to reduce
to output in the the next code chunk display parts of id2.:
id2 <- QFeatures::reduceDataFrame(id, id$spectrumID)
rownames(id2) <- NULL ## rownames not needed here
dim(id2)## [1] 5343 35The resulting object contains a single entrie for scan 1774 with information for the multiple matches stored as lists within the cells.
## DataFrame with 1 row and 35 columns
## sequence spectrumID chargeState rank
## <CharacterList> <character> <integer> <IntegerList>
## 1 RTRYQAEVR,RTRYQAEVR,RTRYQAEVR,... controller... 2 1,1,1,...
## passThreshold experimentalMassToCharge calculatedMassToCharge
## <logical> <numeric> <NumericList>
## 1 TRUE 589.821 589.823,589.823,589.823,...
## peptideRef modNum isDecoy
## <CharacterList> <IntegerList> <LogicalList>
## 1 Pep1890,Pep1890,Pep1890,... 0,0,0,... FALSE,FALSE,FALSE,...
## post pre start end
## <CharacterList> <CharacterList> <IntegerList> <IntegerList>
## 1 P,P,P,... R,R,R,... 89,99,89,... 97,107,97,...
## DatabaseAccess DBseqLength DatabaseSeq
## <CharacterList> <IntegerList> <character>
## 1 ECA2104,ECA2867,ECA3427,... 675,619,678,...
## DatabaseDescription scan.number.s. acquisitionNum
## <CharacterList> <numeric> <numeric>
## 1 ECA2104 Vg...,ECA2867 pu...,ECA3427 co...,... 1774 1774
## spectrumFile idFile MS.GF.RawScore MS.GF.DeNovoScore MS.GF.SpecEValue
## <character> <character> <numeric> <numeric> <numeric>
## 1 TMT_Erwini... TMT_Erwini... 0 96 3.69254e-06
## MS.GF.EValue MS.GF.QValue MS.GF.PepQValue
## <NumericList> <numeric> <NumericList>
## 1 10.5388,10.5388,10.5388,... 1 0.990816,0.990816,0.990816,...
## modPeptideRef modName modMass modLocation
## <CharacterList> <CharacterList> <NumericList> <IntegerList>
## 1 NA,NA,NA,... NA,NA,NA,... NA,NA,NA,... NA,NA,NA,...
## subOriginalResidue subReplacementResidue subLocation
## <character> <character> <integer>
## 1 NA NA NA## CharacterList of length 1
## [["controllerType=0 controllerNumber=1 scan=1774"]] ECA2104 ECA2867 ECA3427 ECA4142The is the type of complete identification table that could be used to
annotate an raw mass spectrometry Spectra object, as shown below.
4.3 Filtering data
Often, the PSM data is filtered to only retain reliable matches. The
MSnID package can be used to set thresholds to attain user-defined
PSM, peptide or protein-level FDRs. Here, we will simply filter out
wrong identification manually.
Here, the filter() from the dplyr package comes very handy. We
will thus start by convering the DataFrame to a tibble.
## # A tibble: 5,802 x 35
## sequence spectrumID chargeState rank passThreshold experimentalMass…
## <chr> <chr> <int> <int> <lgl> <dbl>
## 1 RQCRTDFLNYLR controllerTyp… 3 1 TRUE 548.
## 2 ESVALADQVTC… controllerTyp… 2 1 TRUE 1288.
## 3 KELLCLAMQIIR controllerTyp… 2 1 TRUE 744.
## 4 QRMARTSDKQQ… controllerTyp… 3 1 TRUE 913.
## 5 KDEGSTEPLKV… controllerTyp… 3 1 TRUE 927.
## 6 DGGPAIYGHER… controllerTyp… 3 1 TRUE 969.
## 7 QRMARTSDKQQ… controllerTyp… 2 1 TRUE 1369.
## 8 CIDRARHVEVQ… controllerTyp… 3 1 TRUE 1285.
## 9 CIDRARHVEVQ… controllerTyp… 3 1 TRUE 1285.
## 10 VGRCRPIINYL… controllerTyp… 2 1 TRUE 1102.
## # … with 5,792 more rows, and 29 more variables: calculatedMassToCharge <dbl>,
## # peptideRef <chr>, modNum <int>, isDecoy <lgl>, post <chr>, pre <chr>,
## # start <int>, end <int>, DatabaseAccess <chr>, DBseqLength <int>,
## # DatabaseSeq <chr>, DatabaseDescription <chr>, scan.number.s. <dbl>,
## # acquisitionNum <dbl>, spectrumFile <chr>, idFile <chr>,
## # MS.GF.RawScore <dbl>, MS.GF.DeNovoScore <dbl>, MS.GF.SpecEValue <dbl>,
## # MS.GF.EValue <dbl>, MS.GF.QValue <dbl>, MS.GF.PepQValue <dbl>,
## # modPeptideRef <chr>, modName <chr>, modMass <dbl>, modLocation <int>,
## # subOriginalResidue <chr>, subReplacementResidue <chr>, subLocation <int>Exercise
- Remove decoy hits
## # A tibble: 2,906 x 35
## sequence spectrumID chargeState rank passThreshold experimentalMass…
## <chr> <chr> <int> <int> <lgl> <dbl>
## 1 RQCRTDFLNYLR controllerTyp… 3 1 TRUE 548.
## 2 ESVALADQVTC… controllerTyp… 2 1 TRUE 1288.
## 3 QRMARTSDKQQ… controllerTyp… 3 1 TRUE 913.
## 4 DGGPAIYGHER… controllerTyp… 3 1 TRUE 969.
## 5 QRMARTSDKQQ… controllerTyp… 2 1 TRUE 1369.
## 6 CIDRARHVEVQ… controllerTyp… 3 1 TRUE 1285.
## 7 CIDRARHVEVQ… controllerTyp… 3 1 TRUE 1285.
## 8 VGRCRPIINYL… controllerTyp… 2 1 TRUE 1102.
## 9 QRLDEHCVGVG… controllerTyp… 3 1 TRUE 713.
## 10 VDYQGKKVVII… controllerTyp… 4 1 TRUE 870.
## # … with 2,896 more rows, and 29 more variables: calculatedMassToCharge <dbl>,
## # peptideRef <chr>, modNum <int>, isDecoy <lgl>, post <chr>, pre <chr>,
## # start <int>, end <int>, DatabaseAccess <chr>, DBseqLength <int>,
## # DatabaseSeq <chr>, DatabaseDescription <chr>, scan.number.s. <dbl>,
## # acquisitionNum <dbl>, spectrumFile <chr>, idFile <chr>,
## # MS.GF.RawScore <dbl>, MS.GF.DeNovoScore <dbl>, MS.GF.SpecEValue <dbl>,
## # MS.GF.EValue <dbl>, MS.GF.QValue <dbl>, MS.GF.PepQValue <dbl>,
## # modPeptideRef <chr>, modName <chr>, modMass <dbl>, modLocation <int>,
## # subOriginalResidue <chr>, subReplacementResidue <chr>, subLocation <int>- Keep first rank matches
## # A tibble: 2,751 x 35
## sequence spectrumID chargeState rank passThreshold experimentalMass…
## <chr> <chr> <int> <int> <lgl> <dbl>
## 1 RQCRTDFLNYLR controllerTyp… 3 1 TRUE 548.
## 2 ESVALADQVTC… controllerTyp… 2 1 TRUE 1288.
## 3 QRMARTSDKQQ… controllerTyp… 3 1 TRUE 913.
## 4 DGGPAIYGHER… controllerTyp… 3 1 TRUE 969.
## 5 QRMARTSDKQQ… controllerTyp… 2 1 TRUE 1369.
## 6 CIDRARHVEVQ… controllerTyp… 3 1 TRUE 1285.
## 7 CIDRARHVEVQ… controllerTyp… 3 1 TRUE 1285.
## 8 VGRCRPIINYL… controllerTyp… 2 1 TRUE 1102.
## 9 QRLDEHCVGVG… controllerTyp… 3 1 TRUE 713.
## 10 VDYQGKKVVII… controllerTyp… 4 1 TRUE 870.
## # … with 2,741 more rows, and 29 more variables: calculatedMassToCharge <dbl>,
## # peptideRef <chr>, modNum <int>, isDecoy <lgl>, post <chr>, pre <chr>,
## # start <int>, end <int>, DatabaseAccess <chr>, DBseqLength <int>,
## # DatabaseSeq <chr>, DatabaseDescription <chr>, scan.number.s. <dbl>,
## # acquisitionNum <dbl>, spectrumFile <chr>, idFile <chr>,
## # MS.GF.RawScore <dbl>, MS.GF.DeNovoScore <dbl>, MS.GF.SpecEValue <dbl>,
## # MS.GF.EValue <dbl>, MS.GF.QValue <dbl>, MS.GF.PepQValue <dbl>,
## # modPeptideRef <chr>, modName <chr>, modMass <dbl>, modLocation <int>,
## # subOriginalResidue <chr>, subReplacementResidue <chr>, subLocation <int>- Remove non-proteotypic peptides. Start by identifying scans that
match different proteins. For example scan 4884 matches proteins
XXX_ECA3406andECA3415. Scan 4099 matchXXX_ECA4416_1,XXX_ECA4416_2andXXX_ECA4416_3. Then remove the scans that match any of these proteins.
mltm <-
id_tbl %>%
group_by(spectrumID) %>%
mutate(nProts = length(unique(DatabaseAccess))) %>%
filter(nProts > 1) %>%
select(DatabaseAccess, nProts)## Adding missing grouping variables: `spectrumID`## # A tibble: 85 x 3
## # Groups: spectrumID [39]
## spectrumID DatabaseAccess nProts
## <chr> <chr> <int>
## 1 controllerType=0 controllerNumber=1 scan=1073 ECA2869 2
## 2 controllerType=0 controllerNumber=1 scan=1073 ECA4278 2
## 3 controllerType=0 controllerNumber=1 scan=6578 ECA3480 2
## 4 controllerType=0 controllerNumber=1 scan=6578 ECA3481 2
## 5 controllerType=0 controllerNumber=1 scan=5617 ECA4283 2
## 6 controllerType=0 controllerNumber=1 scan=5617 ECA4292 2
## 7 controllerType=0 controllerNumber=1 scan=3926 ECA0216 2
## 8 controllerType=0 controllerNumber=1 scan=3926 ECA4035 2
## 9 controllerType=0 controllerNumber=1 scan=4784 ECA0216 2
## 10 controllerType=0 controllerNumber=1 scan=4784 ECA4035 2
## # … with 75 more rows## # A tibble: 2,666 x 35
## sequence spectrumID chargeState rank passThreshold experimentalMass…
## <chr> <chr> <int> <int> <lgl> <dbl>
## 1 RQCRTDFLNYLR controllerTyp… 3 1 TRUE 548.
## 2 ESVALADQVTC… controllerTyp… 2 1 TRUE 1288.
## 3 QRMARTSDKQQ… controllerTyp… 3 1 TRUE 913.
## 4 DGGPAIYGHER… controllerTyp… 3 1 TRUE 969.
## 5 QRMARTSDKQQ… controllerTyp… 2 1 TRUE 1369.
## 6 CIDRARHVEVQ… controllerTyp… 3 1 TRUE 1285.
## 7 CIDRARHVEVQ… controllerTyp… 3 1 TRUE 1285.
## 8 VGRCRPIINYL… controllerTyp… 2 1 TRUE 1102.
## 9 QRLDEHCVGVG… controllerTyp… 3 1 TRUE 713.
## 10 VDYQGKKVVII… controllerTyp… 4 1 TRUE 870.
## # … with 2,656 more rows, and 29 more variables: calculatedMassToCharge <dbl>,
## # peptideRef <chr>, modNum <int>, isDecoy <lgl>, post <chr>, pre <chr>,
## # start <int>, end <int>, DatabaseAccess <chr>, DBseqLength <int>,
## # DatabaseSeq <chr>, DatabaseDescription <chr>, scan.number.s. <dbl>,
## # acquisitionNum <dbl>, spectrumFile <chr>, idFile <chr>,
## # MS.GF.RawScore <dbl>, MS.GF.DeNovoScore <dbl>, MS.GF.SpecEValue <dbl>,
## # MS.GF.EValue <dbl>, MS.GF.QValue <dbl>, MS.GF.PepQValue <dbl>,
## # modPeptideRef <chr>, modName <chr>, modMass <dbl>, modLocation <int>,
## # subOriginalResidue <chr>, subReplacementResidue <chr>, subLocation <int>Which leaves us with 2666 PSMs.
This can also be achieved with the filterPSMs() function:
## Starting with 5802 PSMs:## removed 2896 decoy hits## removed 155 PSMs with rank > 1## removed 85 non-proteotypic peptides## 2666 PSMs left.Exercise
Compare the distribution of raw idenfication scores of the decoy and non-decoy hits. Interpret the figure.
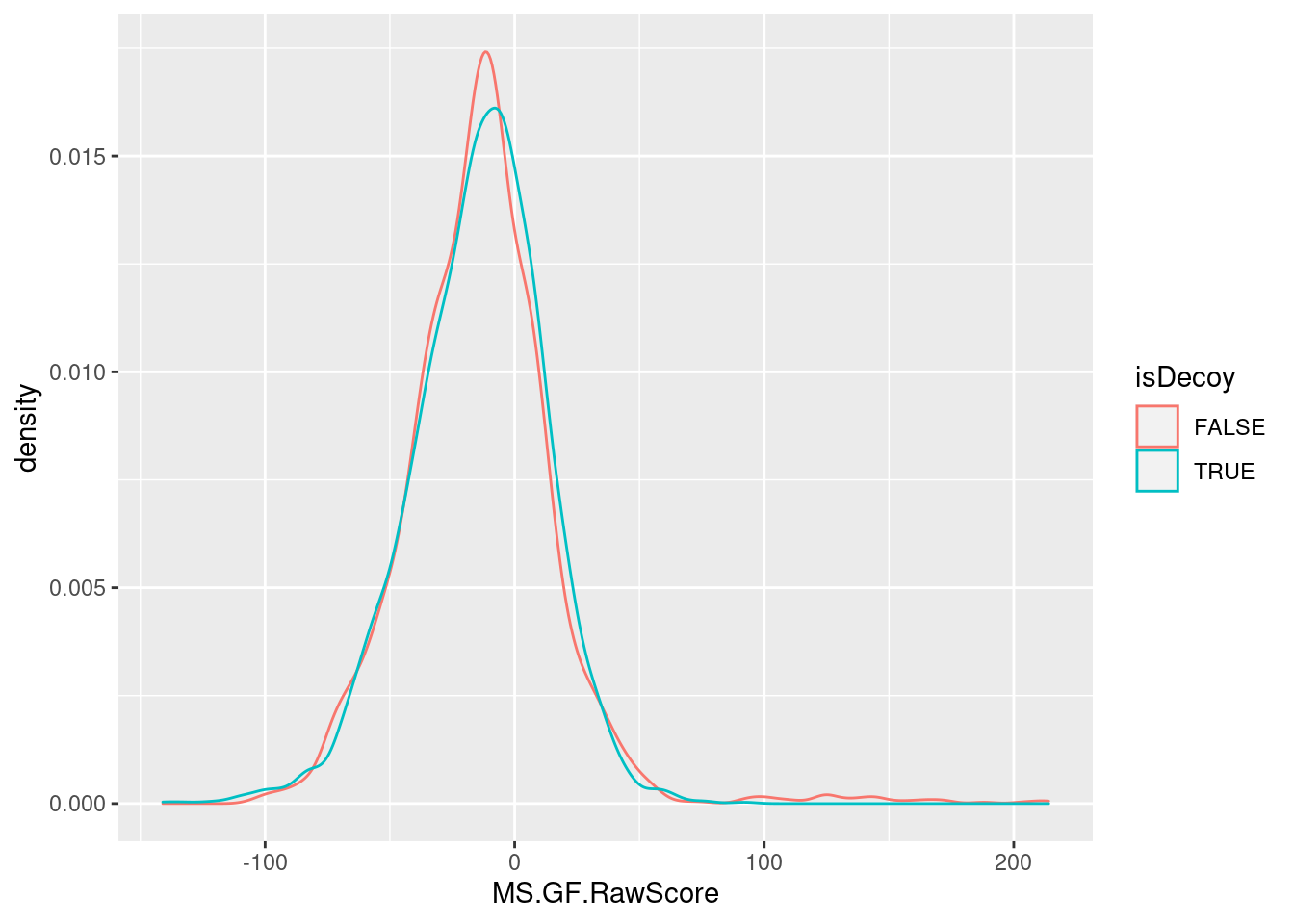
Exercise
The tidyverse
tools are fit for data wrangling with identification data. Using the
above identification dataframe, calculate the length of each peptide
(you can use nchar with the peptide sequence sequence) and the
number of peptides for each protein (defined as
DatabaseDescription). Plot the length of the proteins against their
respective number of peptides.
suppressPackageStartupMessages(library("dplyr"))
iddf <- as_tibble(id_filtered) %>%
mutate(peplen = nchar(sequence))
npeps <- iddf %>%
group_by(DatabaseAccess) %>%
tally
iddf <- full_join(iddf, npeps)## Joining, by = "DatabaseAccess"Figure 4.1: Identifcation data wrangling.
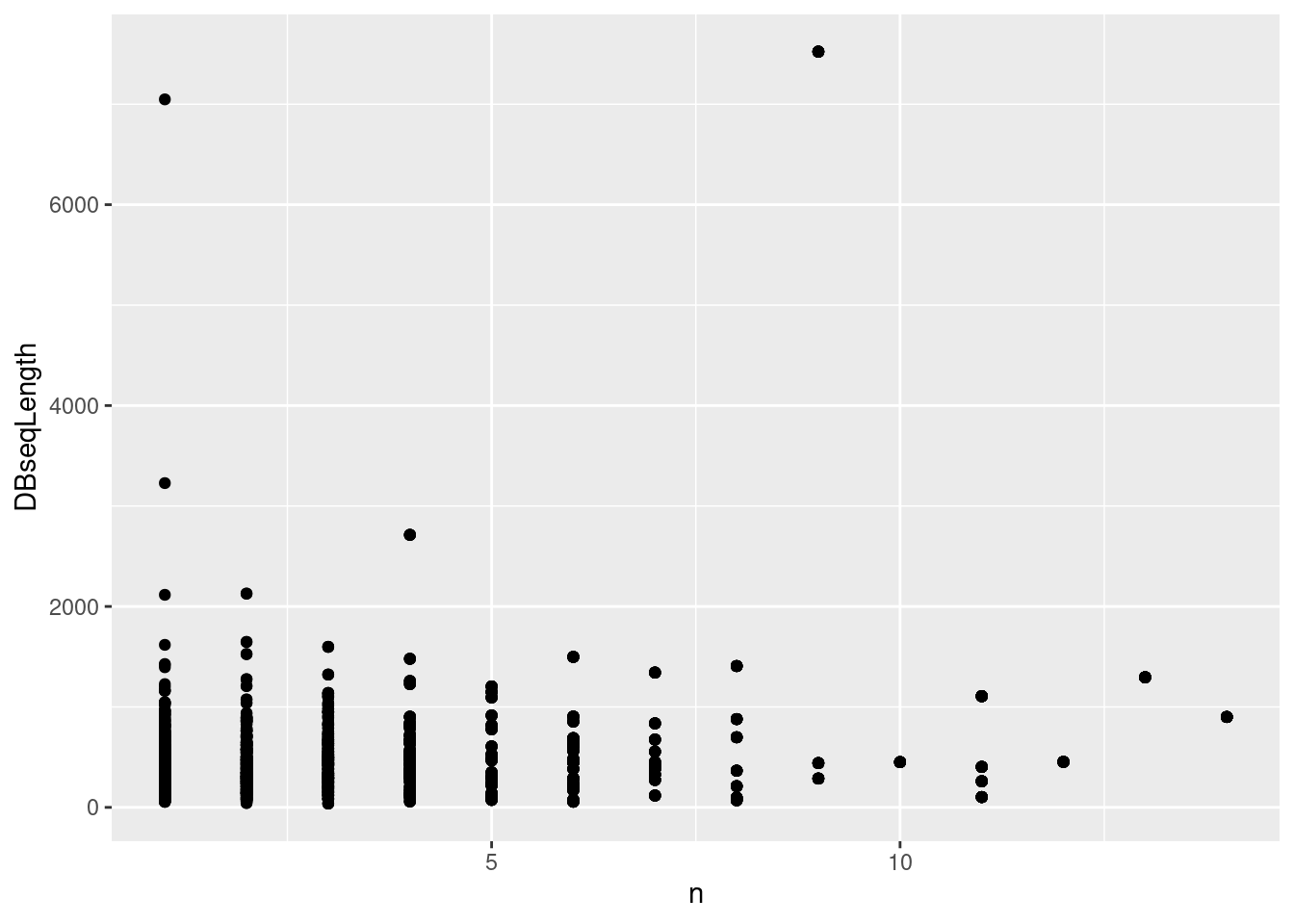
4.4 Low level access to id data (optional)
There are two packages that can be used to parse mzIdentML files,
namely mzR (that we have already used for raw data) and mzID. The
major difference is that the former leverages C++ code from
proteowizard and is hence faster than the latter (which uses the
XML R package). They both work in similar ways.
|Data type |File format |Data structure |Package |
|:--------------|:-----------|:--------------|:-------|
|Identification |mzIdentML |mzRident |mzR |
|Identification |mzIdentML |mzID |mzID |Which of these packages is used by readPSMs() can be defined by the
parser argument.
mzID
The main functions are mzID to read the data into a dedicated data
class and flatten to transform it into a data.frame.
## [1] "/home/lgatto/R/x86_64-pc-linux-gnu-library/4.0/msdata/ident/TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzid"##
## Attaching package: 'mzID'## The following object is masked from 'package:dplyr':
##
## id## reading TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzid... DONE!## An mzID object
##
## Software used: MS-GF+ (version: Beta (v10072))
##
## Rawfile: /home/lg390/dev/01_svn/workflows/proteomics/TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML
##
## Database: /home/lg390/dev/01_svn/workflows/proteomics/erwinia_carotovora.fasta
##
## Number of scans: 5343
## Number of PSM's: 5656Various data can be extracted from the mzID object, using one the
accessor functions such as database, software, scans, peptides,
… The object can also be converted into a data.frame using the
flatten function.
## spectrumid scan number(s) acquisitionnum
## 1 controllerType=0 controllerNumber=1 scan=5782 5782 5782
## 2 controllerType=0 controllerNumber=1 scan=6037 6037 6037
## 3 controllerType=0 controllerNumber=1 scan=5235 5235 5235
## passthreshold rank calculatedmasstocharge experimentalmasstocharge
## 1 TRUE 1 1080.232 1080.233
## 2 TRUE 1 1002.212 1002.209
## 3 TRUE 1 1189.280 1189.284
## chargestate ms-gf:denovoscore ms-gf:evalue ms-gf:pepqvalue ms-gf:qvalue
## 1 3 174 1.086033e-20 0 0
## 2 3 245 1.988774e-19 0 0
## 3 3 264 5.129649e-19 0 0
## ms-gf:rawscore ms-gf:specevalue assumeddissociationmethod isotopeerror
## 1 147 3.764831e-27 HCD 0
## 2 214 6.902626e-26 HCD 0
## 3 211 1.778789e-25 HCD 0
## isdecoy post pre end start accession length
## 1 FALSE S R 84 50 ECA1932 155
## 2 FALSE R K 315 288 ECA1147 434
## 3 FALSE A R 224 192 ECA0013 295
## description pepseq
## 1 outer membrane lipoprotein PVQIQAGEDSNVIGALGGAVLGGFLGNTIGGGSGR
## 2 trigger factor TQVLDGLINANDIEVPVALIDGEIDVLR
## 3 ribose-binding periplasmic protein TKGLNVMQNLLTAHPDVQAVFAQNDEMALGALR
## modified modification
## 1 FALSE <NA>
## 2 FALSE <NA>
## 3 FALSE <NA>
## idFile
## 1 TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzid
## 2 TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzid
## 3 TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzid
## spectrumFile
## 1 TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML
## 2 TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML
## 3 TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML
## databaseFile
## 1 erwinia_carotovora.fasta
## 2 erwinia_carotovora.fasta
## 3 erwinia_carotovora.fasta
## [ reached 'max' / getOption("max.print") -- omitted 3 rows ]mzR
The mzR interface provides a similar interface. It is however much
faster as it does not read all the data into memory and only extracts
relevant data on demand. It has also accessor functions such as
softwareInfo, mzidInfo, … (use showMethods(classes = "mzRident", where = "package:mzR"))
to see all available methods.
## Identification file handle.
## Filename: TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzid
## Number of psms: 5759## [1] "MS-GF+ Beta (v10072) "
## [2] "ProteoWizard MzIdentML 3.0.501 ProteoWizard"The identification data can be accessed as a data.frame with the
psms accessor.
## spectrumID chargeState rank passThreshold
## 1 controllerType=0 controllerNumber=1 scan=5782 3 1 TRUE
## 2 controllerType=0 controllerNumber=1 scan=6037 3 1 TRUE
## 3 controllerType=0 controllerNumber=1 scan=5235 3 1 TRUE
## 4 controllerType=0 controllerNumber=1 scan=5397 3 1 TRUE
## 5 controllerType=0 controllerNumber=1 scan=6075 3 1 TRUE
## experimentalMassToCharge calculatedMassToCharge
## 1 1080.2325 1080.2321
## 2 1002.2089 1002.2115
## 3 1189.2836 1189.2800
## 4 960.5365 960.5365
## 5 1264.3409 1264.3419
## sequence peptideRef modNum isDecoy post pre start
## 1 PVQIQAGEDSNVIGALGGAVLGGFLGNTIGGGSGR Pep1 0 FALSE S R 50
## 2 TQVLDGLINANDIEVPVALIDGEIDVLR Pep2 0 FALSE R K 288
## 3 TKGLNVMQNLLTAHPDVQAVFAQNDEMALGALR Pep3 0 FALSE A R 192
## 4 SQILQQAGTSVLSQANQVPQTVLSLLR Pep4 0 FALSE - R 264
## 5 PIIGDNPFVVVLPDVVLDESTADQTQENLALLISR Pep5 0 FALSE F R 119
## end DatabaseAccess DBseqLength DatabaseSeq
## 1 84 ECA1932 155
## 2 315 ECA1147 434
## 3 224 ECA0013 295
## 4 290 ECA1731 290
## 5 153 ECA1443 298
## DatabaseDescription scan.number.s.
## 1 ECA1932 outer membrane lipoprotein 5782
## 2 ECA1147 trigger factor 6037
## 3 ECA0013 ribose-binding periplasmic protein 5235
## 4 ECA1731 flagellin 5397
## 5 ECA1443 UTP--glucose-1-phosphate uridylyltransferase 6075
## acquisitionNum
## 1 5782
## 2 6037
## 3 5235
## 4 5397
## 5 6075
## [ reached 'max' / getOption("max.print") -- omitted 1 rows ]4.5 MS/MS database search
While searches are generally performed using third-party software
independently of R or can be started from R using a system call, the
MSGFplus package enables to perform a search using the
MSGF+ engine, as illustrated below.
We search the
TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML.gz
file against the fasta file from PXD000001 using MSGFplus.
We first download the fasta files from ProteomeXchange:
Below, we setup and run the
search6 In the runMSGF call, the memory allocated to the java virtual machine is limited to 1GB. In general, there is no need to specify this argument, unless you experience an error regarding the maximum heap size..
library("MSGFplus")
msgfpar <- msgfPar(database = fas,
instrument = 'HighRes',
tda = TRUE,
enzyme = 'Trypsin',
protocol = 'iTRAQ')
idres <- runMSGF(msgfpar, mzf, memory=1000)
idres## An mzID object
##
## Software used: MS-GF+ (version: Beta (v10072))
##
## Rawfile: /home/lg390/Documents/Teaching/bioc-ms-prot/TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML
##
## Database: /home/lg390/Documents/Teaching/bioc-ms-prot/erwinia_carotovora.fasta
##
## Number of scans: 5343
## Number of PSM's: 5656A graphical interface to perform the search the data and explore the results is also available:
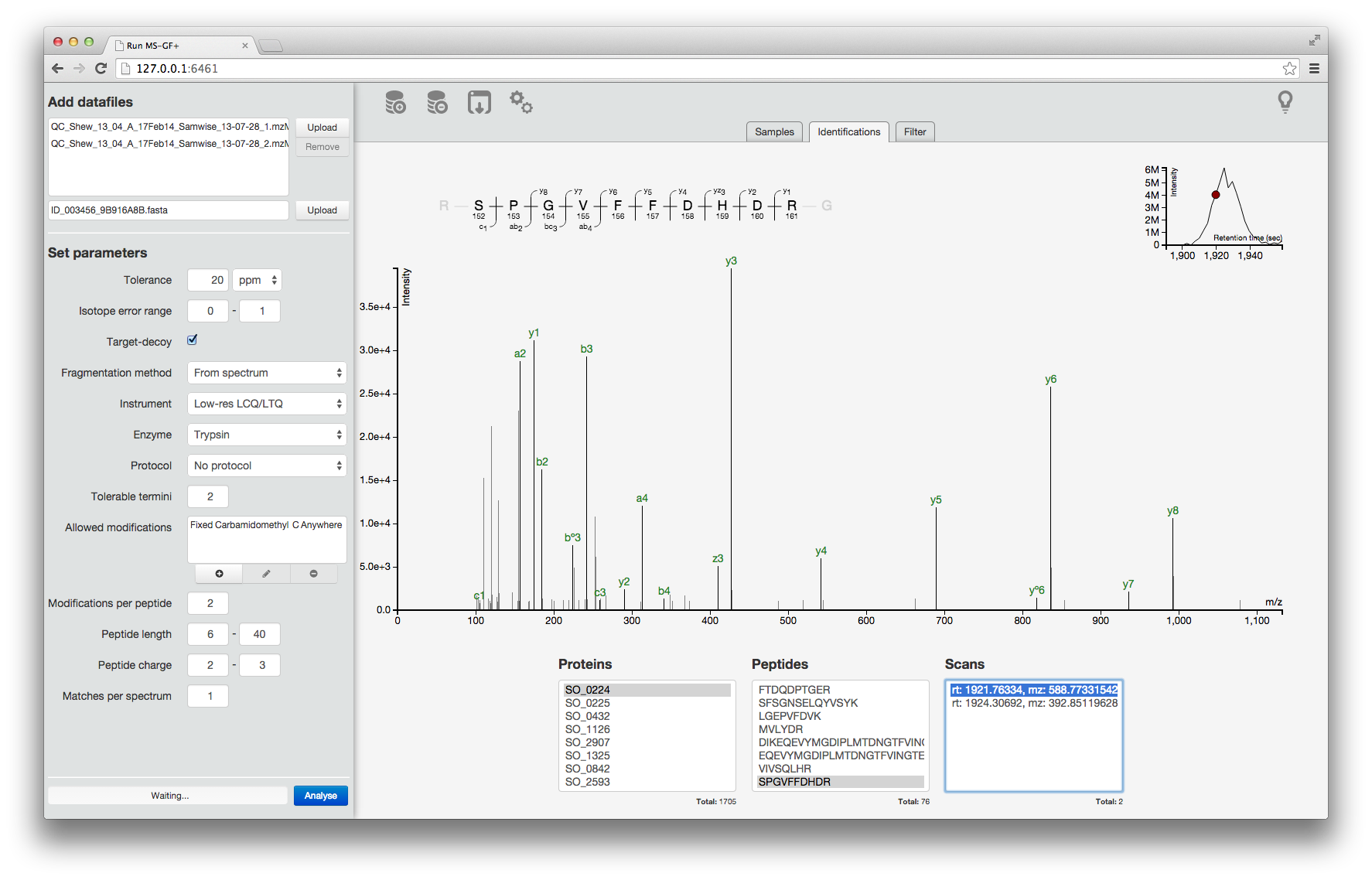
The MSGFgui interface
4.6 Adding identification data to raw data
We are goind to use the sp object created in the previous chapter
and the id_filtered variable generated above.
Identification data (as a DataFrame) can be merged into raw data (as
a Spectra object) by adding new spectra variables to the appropriate
MS2 spectra. Scans and peptide-spectrum matches can be matched by
their spectrum identifers.
Exercise
Identify the spectum identifier columns in the sp the id_filtered
variables.
In the raw data, it is encoded as spectrumId, while in the
identification data, we have spectrumID.
## [1] "msLevel" "rtime"
## [3] "acquisitionNum" "scanIndex"
## [5] "dataStorage" "dataOrigin"
## [7] "centroided" "smoothed"
## [9] "polarity" "precScanNum"
## [11] "precursorMz" "precursorIntensity"
## [13] "precursorCharge" "collisionEnergy"
## [15] "isolationWindowLowerMz" "isolationWindowTargetMz"
## [17] "isolationWindowUpperMz" "peaksCount"
## [19] "totIonCurrent" "basePeakMZ"
## [21] "basePeakIntensity" "ionisationEnergy"
## [23] "lowMZ" "highMZ"
## [25] "mergedScan" "mergedResultScanNum"
## [27] "mergedResultStartScanNum" "mergedResultEndScanNum"
## [29] "injectionTime" "filterString"
## [31] "spectrumId" "ionMobilityDriftTime"
## [33] "scanWindowLowerLimit" "scanWindowUpperLimit"## [1] "sequence" "spectrumID"
## [3] "chargeState" "rank"
## [5] "passThreshold" "experimentalMassToCharge"
## [7] "calculatedMassToCharge" "peptideRef"
## [9] "modNum" "isDecoy"
## [11] "post" "pre"
## [13] "start" "end"
## [15] "DatabaseAccess" "DBseqLength"
## [17] "DatabaseSeq" "DatabaseDescription"
## [19] "scan.number.s." "acquisitionNum"
## [21] "spectrumFile" "idFile"
## [23] "MS.GF.RawScore" "MS.GF.DeNovoScore"
## [25] "MS.GF.SpecEValue" "MS.GF.EValue"
## [27] "MS.GF.QValue" "MS.GF.PepQValue"
## [29] "modPeptideRef" "modName"
## [31] "modMass" "modLocation"
## [33] "subOriginalResidue" "subReplacementResidue"
## [35] "subLocation"These two data can thus simply be joined using:
sp <- joinSpectraData(sp, id_filtered,
by.x = "spectrumId",
by.y = "spectrumID")
spectraVariables(sp)## [1] "msLevel" "rtime"
## [3] "acquisitionNum" "scanIndex"
## [5] "dataStorage" "dataOrigin"
## [7] "centroided" "smoothed"
## [9] "polarity" "precScanNum"
## [11] "precursorMz" "precursorIntensity"
## [13] "precursorCharge" "collisionEnergy"
## [15] "isolationWindowLowerMz" "isolationWindowTargetMz"
## [17] "isolationWindowUpperMz" "peaksCount"
## [19] "totIonCurrent" "basePeakMZ"
## [21] "basePeakIntensity" "ionisationEnergy"
## [23] "lowMZ" "highMZ"
## [25] "mergedScan" "mergedResultScanNum"
## [27] "mergedResultStartScanNum" "mergedResultEndScanNum"
## [29] "injectionTime" "filterString"
## [31] "spectrumId" "ionMobilityDriftTime"
## [33] "scanWindowLowerLimit" "scanWindowUpperLimit"
## [35] "sequence" "chargeState"
## [37] "rank" "passThreshold"
## [39] "experimentalMassToCharge" "calculatedMassToCharge"
## [41] "peptideRef" "modNum"
## [43] "isDecoy" "post"
## [45] "pre" "start"
## [47] "end" "DatabaseAccess"
## [49] "DBseqLength" "DatabaseSeq"
## [51] "DatabaseDescription" "scan.number.s."
## [53] "acquisitionNum.y" "spectrumFile"
## [55] "idFile" "MS.GF.RawScore"
## [57] "MS.GF.DeNovoScore" "MS.GF.SpecEValue"
## [59] "MS.GF.EValue" "MS.GF.QValue"
## [61] "MS.GF.PepQValue" "modPeptideRef"
## [63] "modName" "modMass"
## [65] "modLocation" "subOriginalResidue"
## [67] "subReplacementResidue" "subLocation"Exercise
Verify that the identification data has been added to the correct spectra.
- Let’s first verify that no identification data has been added to the MS1 scans.
## [1] TRUE- They have indeed been added to 56% of the MS2 spectra.
##
## FALSE TRUE
## 2646 3457- Let’s compare the precursor/peptide mass to charges
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0000 0.0000 0.0000 0.0053 0.0000 2.02974.7 Visualising peptide-spectrum matches
Let’s choose a MS2 spectrum with a high identication score and plot it.
We have seen above that we can add labels to each peak using the
labels argument in plotSpectra(). The addFragments() function
takes a spectrum as input (that is a Spectra object of length 1) and
annotates its peaks.
## [1] NA NA NA "b1" NA NA NA NA NA NA NA NA
## [13] NA NA NA NA NA NA NA NA NA NA NA NA
## [25] NA NA NA NA NA NA NA NA NA NA NA NA
## [37] NA NA NA NA NA NA NA "y1_" NA NA NA NA
## [49] NA "y1" NA NA NA NA NA NA NA NA NA NA
## [61] NA NA NA NA NA NA NA NA NA NA NA NA
## [73] NA NA NA NA NA NA NA NA NA NA NA NA
## [85] NA NA "b2" NA NA NA NA NA NA NA NA NA
## [97] NA NA NA NA
## [ reached getOption("max.print") -- omitted 227 entries ]It can be directly used with plotSpectra():
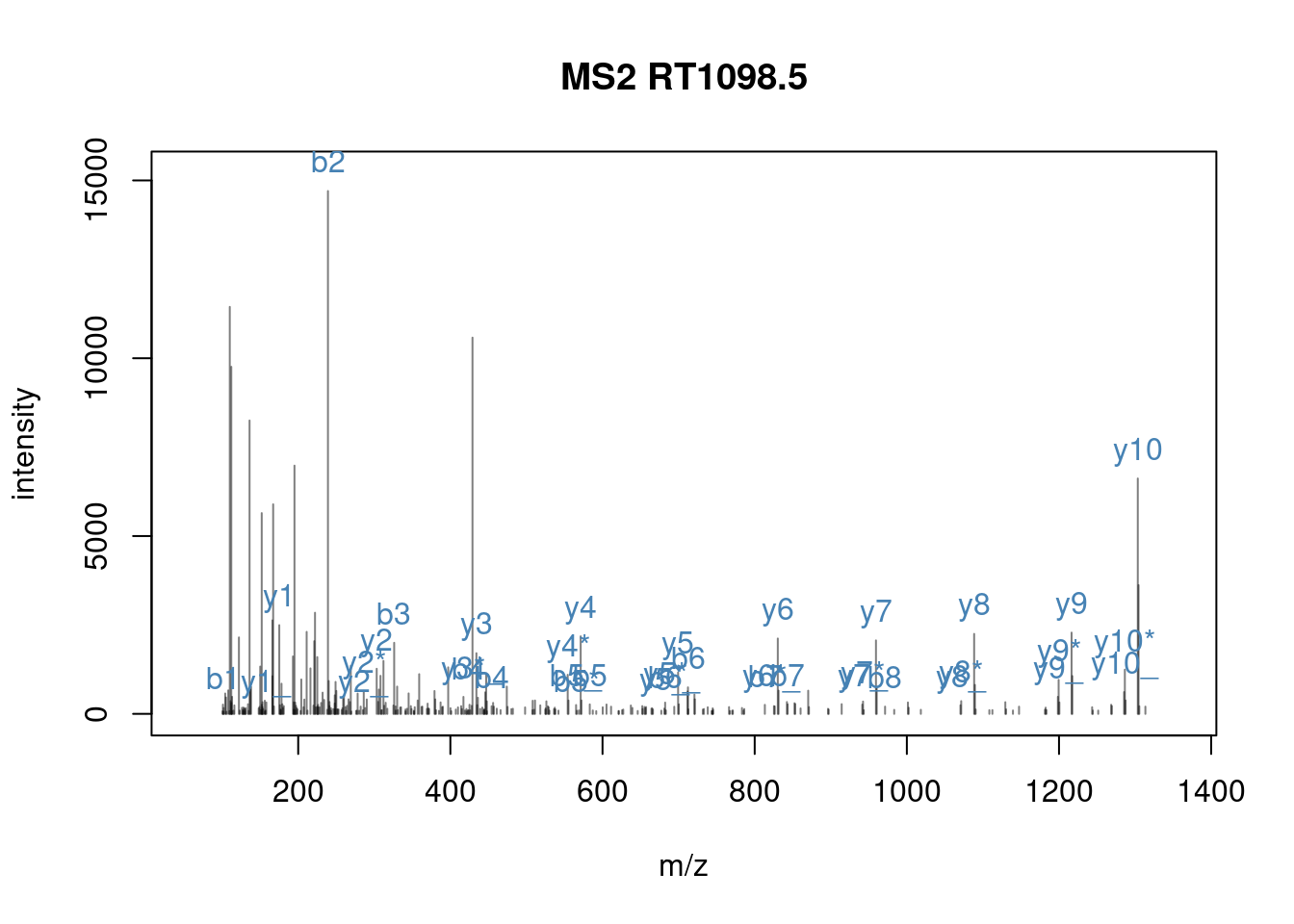
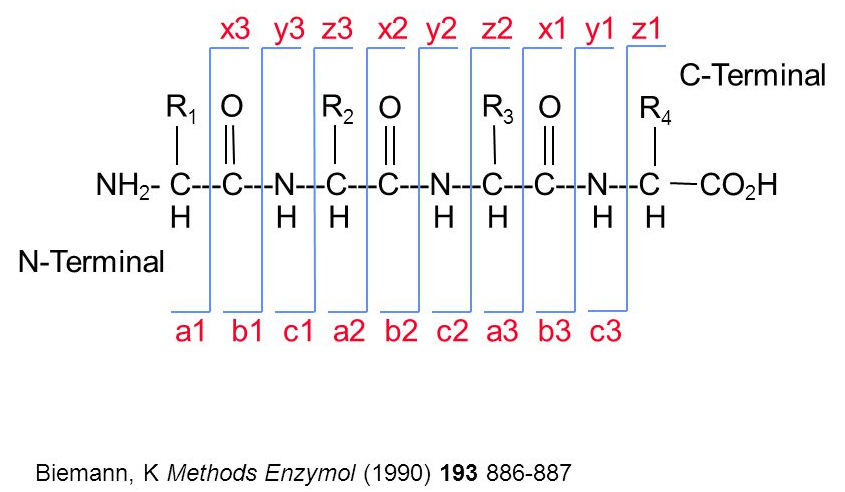
When a precursor peptide ion is fragmented in a CID cell, it breaks at specific bonds, producing sets of peaks (a, b, c and x, y, z) that can be predicted.
(#fig:frag_img)Peptide fragmentation.
The annotation of spectra is obtained by simulating fragmentation of a peptide and matching observed peaks to fragments:
## [1] "THSQEEMQHMQR"## Modifications used: C=57.02146## mz ion type pos z seq
## 1 102.0550 b1 b 1 1 T
## 2 239.1139 b2 b 2 1 TH
## 3 326.1459 b3 b 3 1 THS
## 4 454.2045 b4 b 4 1 THSQ
## 5 583.2471 b5 b 5 1 THSQE
## 6 712.2897 b6 b 6 1 THSQEE
## 7 843.3301 b7 b 7 1 THSQEEM
## 8 971.3887 b8 b 8 1 THSQEEMQ
## 9 1108.4476 b9 b 9 1 THSQEEMQH
## 10 1239.4881 b10 b 10 1 THSQEEMQHM
## 11 1367.5467 b11 b 11 1 THSQEEMQHMQ
## 12 175.1190 y1 y 1 1 R
## 13 303.1775 y2 y 2 1 QR
## 14 434.2180 y3 y 3 1 MQR
## 15 571.2769 y4 y 4 1 HMQR
## 16 699.3355 y5 y 5 1 QHMQR
## [ reached 'max' / getOption("max.print") -- omitted 42 rows ]4.8 Comparing spectra
The compareSpectra() can be used to compare spectra (by default,
computing the normalised dot product).
Exercise
- Create a new
Spectraobject containing the MS2 spectra with sequences"SQILQQAGTSVLSQANQVPQTVLSLLR"and"TKGLNVMQNLLTAHPDVQAVFAQNDEMALGALR".
k <- which(sp$sequence %in% c("SQILQQAGTSVLSQANQVPQTVLSLLR", "TKGLNVMQNLLTAHPDVQAVFAQNDEMALGALR"))
sp_k <- sp[k]
sp_k## MSn data (Spectra) with 5 spectra in a MsBackendMzR backend:
## msLevel rtime scanIndex
## <integer> <numeric> <integer>
## 1 2 2687.42 5230
## 2 2 2688.88 5235
## 3 2 2748.75 5397
## 4 2 2765.26 5442
## 5 2 2768.17 5449
## ... 67 more variables/columns.
##
## file(s):
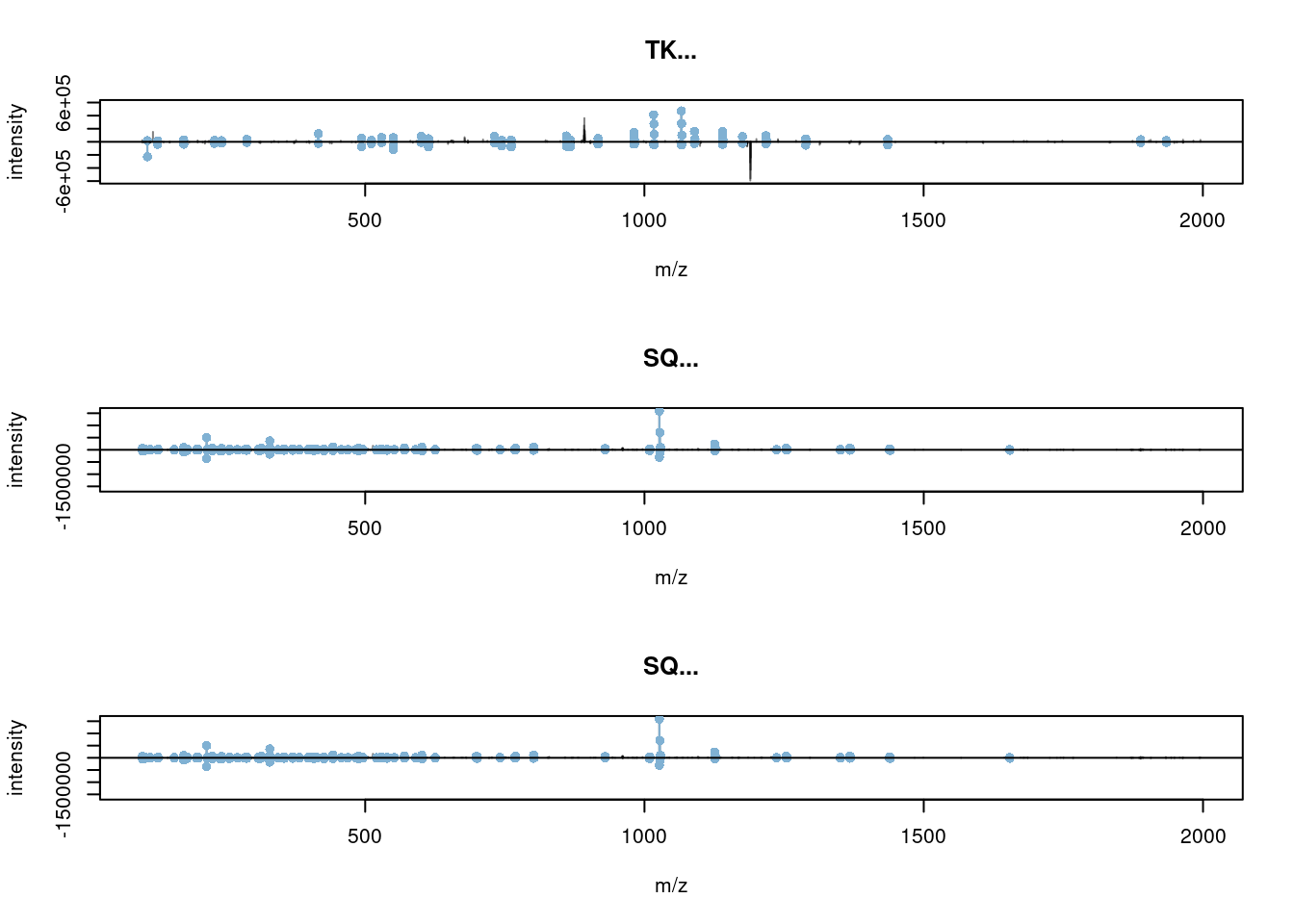
## 10c1f4e4c6980_TMT_Erwinia_1uLSike_Top10HCD_isol2_45stepped_60min_01-20141210.mzML- Calculate the 5 by 5 distance matrix
between all spectra using
compareSpectra. See the?Spectraman page for details. Draw a heatmap of that distance matrix
distmat <- compareSpectra(sp_k)
rownames(distmat) <- colnames(distmat) <- strtrim(sp_k$sequence, 2)
distmat## TK TK SQ SQ SQ
## TK 1.0000000000 0.109126094 0.0009373465 0.001261338 0.0008256185
## TK 0.1091260942 1.000000000 0.0025314670 0.001459654 0.0017613212
## SQ 0.0009373465 0.002531467 1.0000000000 0.432133016 0.6879331218
## SQ 0.0012613380 0.001459654 0.4321330158 1.000000000 0.4467153012
## SQ 0.0008256185 0.001761321 0.6879331218 0.446715301 1.0000000000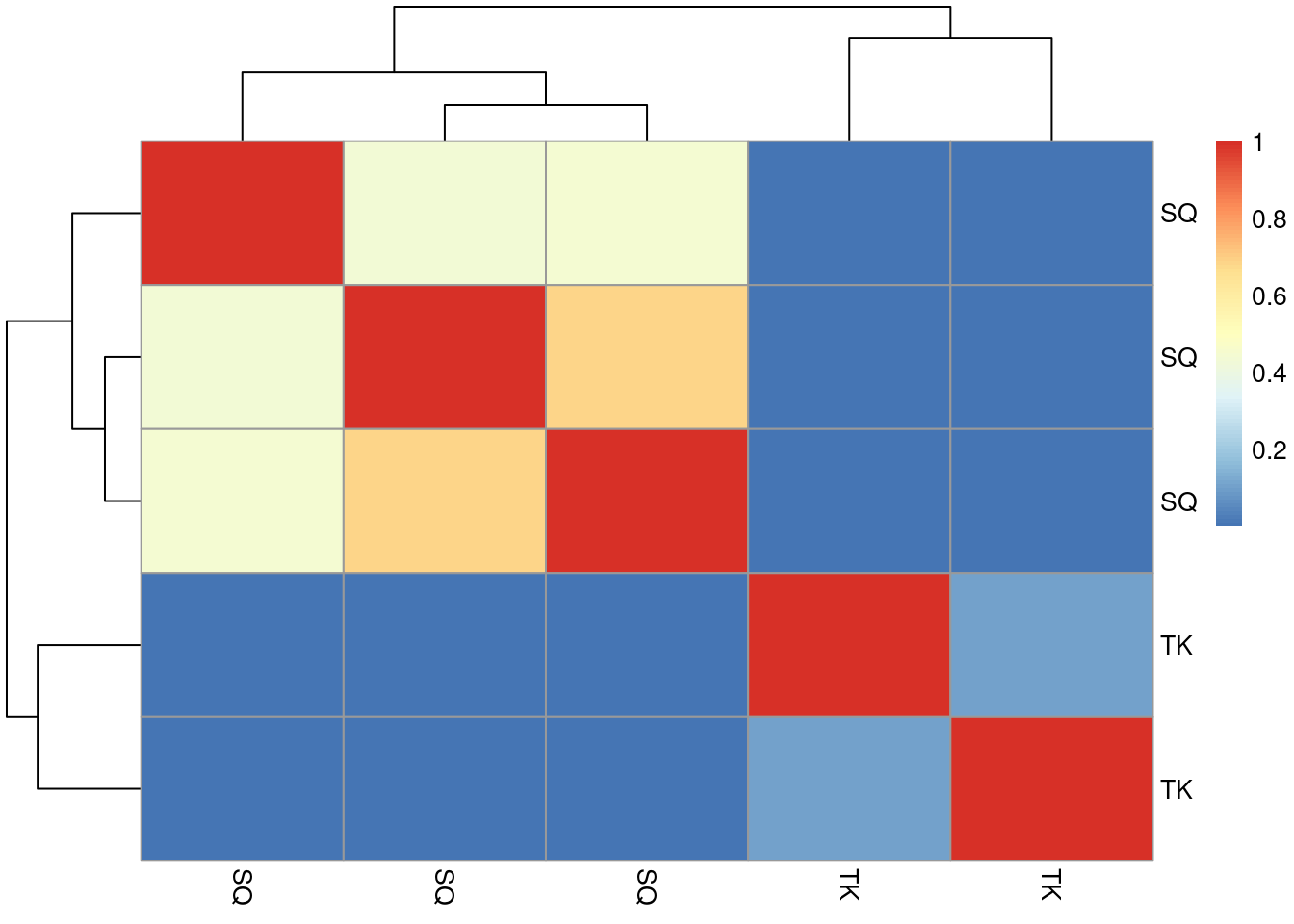
- Compare the spectra with the plotting function seen previously.
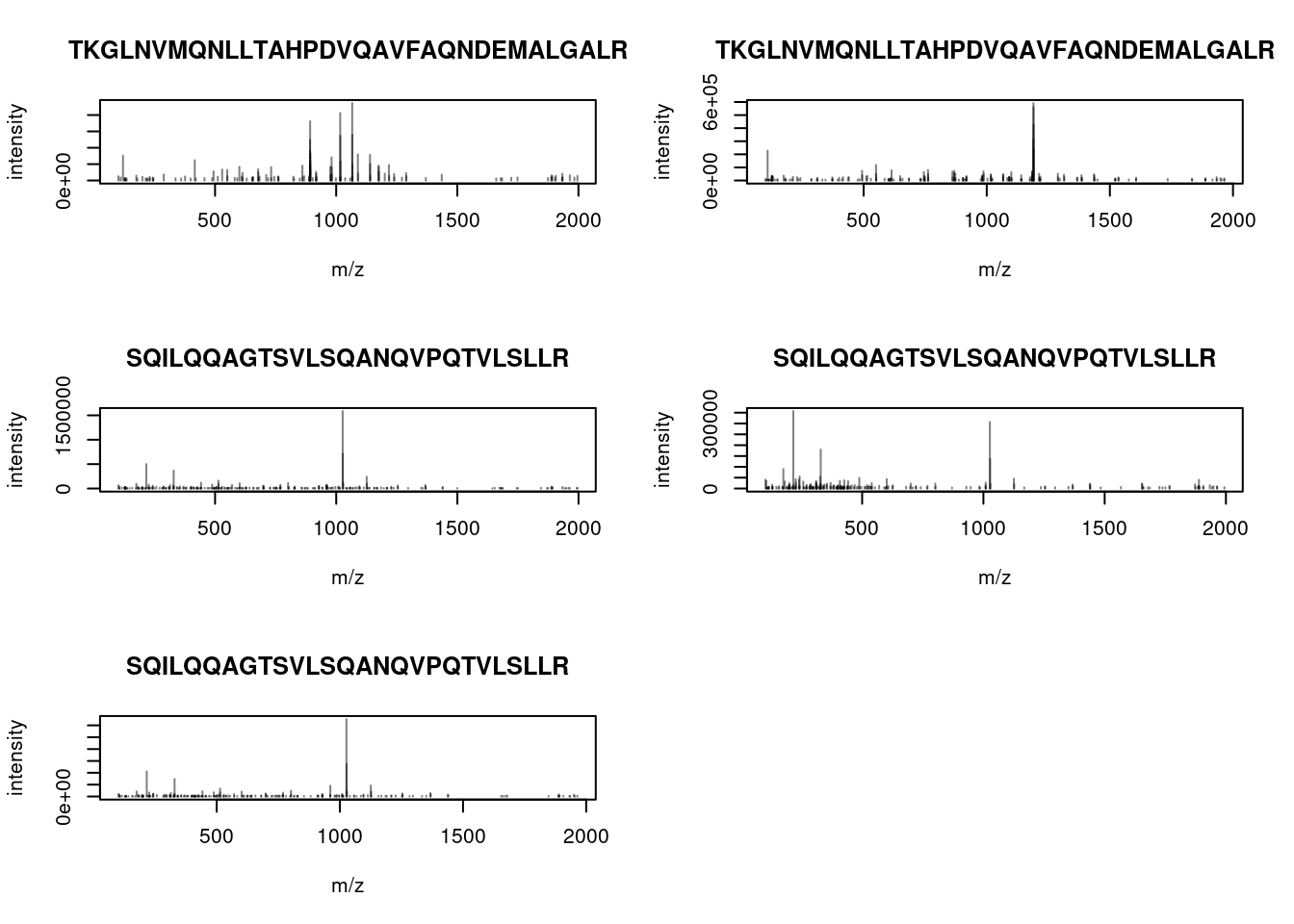
4.9 Summary exercice
Download the 3 first mzML and mzID files from the PXD022816 project. Hint: you will need to execute
rpx:::apply_fix_issue_5(FALSE)before instantiating the data object.Generate a
Spectraobject containing only MS2 scans and a table of filtered PSMs. Check the quality of the identification data by comparing the density of the decoy and forward PSMs id scores for each file. What is the proportion of identified MS2 spectra?Join the raw and identification data. Beware though that the joining must now be performed by spectrum ids and by files.
Extract the PSMs for
"DGSDEPGTAACPNGSFHCTNTGYK","DGQVINETSQHHDDLE"and"DSYVGDEAQSK"and compare and cluster the scans. Hint: once you have created the smallerSpectraobject with the scans of interest, switch to an in-memory backend to seed up the calculations.
4.10 Exploration and Assessment of Identifications using MSnID
The MSnID package extracts MS/MS ID data from mzIdentML (leveraging
the mzID package) or text files. After collating the search results
from multiple datasets it assesses their identification quality and
optimises filtering criteria to achieve the maximum number of
identifications while not exceeding a specified false discovery
rate. It also contains a number of utilities to explore the MS/MS
results and assess missed and irregular enzymatic cleavages, mass
measurement accuracy, etc.
4.10.1 Step-by-step work-flow
Let’s reproduce parts of the analysis described the MSnID
vignette. You can explore more with
The MSnID package can be used for post-search filtering
of MS/MS identifications. One starts with the construction of an
MSnID object that is populated with identification results that can
be imported from a data.frame or from mzIdenML files. Here, we
will use the example identification data provided with the package.
## [1] "c_elegans.mzid.gz"We start by loading the package, initialising the MSnID object, and
add the identification result from our mzid file (there could of
course be more that one).
## Warning: multiple methods tables found for 'quantify'##
## Attaching package: 'MSnID'## The following object is masked from 'package:ProtGenerics':
##
## peptides## Note, the anticipated/suggested columns in the
## peptide-to-spectrum matching results are:
## -----------------------------------------------
## accession
## calculatedMassToCharge
## chargeState
## experimentalMassToCharge
## isDecoy
## peptide
## spectrumFile
## spectrumID## Loaded cached data## MSnID object
## Working directory: "."
## #Spectrum Files: 1
## #PSMs: 12263 at 36 % FDR
## #peptides: 9489 at 44 % FDR
## #accessions: 7414 at 76 % FDRPrinting the MSnID object returns some basic information such as
- Working directory.
- Number of spectrum files used to generate data.
- Number of peptide-to-spectrum matches and corresponding FDR.
- Number of unique peptide sequences and corresponding FDR.
- Number of unique proteins or amino acid sequence accessions and corresponding FDR.
The package then enables to define, optimise and apply filtering based for example on missed cleavages, identification scores, precursor mass errors, etc. and assess PSM, peptide and protein FDR levels. To properly function, it expects to have access to the following data
## [1] "accession" "calculatedMassToCharge"
## [3] "chargeState" "experimentalMassToCharge"
## [5] "isDecoy" "peptide"
## [7] "spectrumFile" "spectrumID"which are indeed present in our data:
## [1] "spectrumID" "scan number(s)"
## [3] "acquisitionNum" "passThreshold"
## [5] "rank" "calculatedMassToCharge"
## [7] "experimentalMassToCharge" "chargeState"
## [9] "MS-GF:DeNovoScore" "MS-GF:EValue"
## [11] "MS-GF:PepQValue" "MS-GF:QValue"
## [13] "MS-GF:RawScore" "MS-GF:SpecEValue"
## [15] "AssumedDissociationMethod" "IsotopeError"
## [17] "isDecoy" "post"
## [19] "pre" "end"
## [21] "start" "accession"
## [23] "length" "description"
## [25] "pepSeq" "modified"
## [27] "modification" "idFile"
## [29] "spectrumFile" "databaseFile"
## [31] "peptide"Here, we summarise a few steps and redirect the reader to the package’s vignette for more details:
4.10.2 Analysis of peptide sequences
Cleaning irregular cleavages at the termini of the peptides and
missing cleavage site within the peptide sequences. The following two
function call create the new numMisCleavages and numIrregCleavages
columns in the MSnID object
4.10.3 Trimming the data
Now, we can use the apply_filter function to effectively apply
filters. The strings passed to the function represent expressions that
will be evaluated, thus keeping only PSMs that have 0 irregular
cleavages and 2 or less missed cleavages.
msnid <- apply_filter(msnid, "numIrregCleavages == 0")
msnid <- apply_filter(msnid, "numMissCleavages <= 2")
show(msnid)## MSnID object
## Working directory: "."
## #Spectrum Files: 1
## #PSMs: 7838 at 17 % FDR
## #peptides: 5598 at 23 % FDR
## #accessions: 3759 at 53 % FDR4.10.4 Parent ion mass errors
Using "calculatedMassToCharge" and "experimentalMassToCharge", the
mass_measurement_error function calculates the parent ion mass
measurement error in parts per million.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -2184.0640 -0.6992 0.0000 17.6146 0.7512 2012.5178We then filter any matches that do not fit the +/- 20 ppm tolerance
msnid <- apply_filter(msnid, "abs(mass_measurement_error(msnid)) < 20")
summary(mass_measurement_error(msnid))## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -19.7797 -0.5866 0.0000 -0.2970 0.5713 19.67584.10.5 Filtering criteria
Filtering of the identification data will rely on
- -log10 transformed MS-GF+ Spectrum E-value, reflecting the goodness of match experimental and theoretical fragmentation patterns
- the absolute mass measurement error (in ppm units) of the parent ion
4.10.6 Setting filters
MS2 filters are handled by a special MSnIDFilter class objects, where
individual filters are set by name (that is present in names(msnid))
and comparison operator (>, <, = , …) defining if we should retain
hits with higher or lower given the threshold and finally the
threshold value itself.
filtObj <- MSnIDFilter(msnid)
filtObj$absParentMassErrorPPM <- list(comparison="<", threshold=10.0)
filtObj$msmsScore <- list(comparison=">", threshold=10.0)
show(filtObj)## MSnIDFilter object
## (absParentMassErrorPPM < 10) & (msmsScore > 10)We can then evaluate the filter on the identification data object, which return the false discovery rate and number of retained identifications for the filtering criteria at hand.
## fdr n
## PSM 0 3807
## peptide 0 2455
## accession 0 10094.10.7 Filter optimisation
Rather than setting filtering values by hand, as shown above, these can be set automatically to meet a specific false discovery rate.
filtObj.grid <- optimize_filter(filtObj, msnid, fdr.max=0.01,
method="Grid", level="peptide",
n.iter=500)
show(filtObj.grid)## MSnIDFilter object
## (absParentMassErrorPPM < 3) & (msmsScore > 7.4)## fdr n
## PSM 0.004097561 5146
## peptide 0.006447651 3278
## accession 0.021996616 1208Filters can eventually be applied (rather than just evaluated) using
the apply_filter function.
## MSnID object
## Working directory: "."
## #Spectrum Files: 1
## #PSMs: 5146 at 0.41 % FDR
## #peptides: 3278 at 0.64 % FDR
## #accessions: 1208 at 2.2 % FDRAnd finally, identifications that matched decoy and contaminant protein sequences are removed
msnid <- apply_filter(msnid, "isDecoy == FALSE")
msnid <- apply_filter(msnid, "!grepl('Contaminant',accession)")
show(msnid)## MSnID object
## Working directory: "."
## #Spectrum Files: 1
## #PSMs: 5117 at 0 % FDR
## #peptides: 3251 at 0 % FDR
## #accessions: 1179 at 0 % FDR
4.10.8 Export MSnID data
The resulting filtered identification data can be exported to a
data.frame (or to a dedicated MSnSet data structure from the
MSnbase package) for quantitative MS data, described below, and
further processed and analyses using appropriate statistical tests.
## spectrumID scan number(s) acquisitionNum passThreshold rank
## 1 index=7151 8819 7151 TRUE 1
## 2 index=8520 10419 8520 TRUE 1
## calculatedMassToCharge experimentalMassToCharge chargeState MS-GF:DeNovoScore
## 1 1270.318 1270.318 3 287
## 2 1426.737 1426.739 3 270
## MS-GF:EValue MS-GF:PepQValue MS-GF:QValue MS-GF:RawScore MS-GF:SpecEValue
## 1 1.709082e-24 0 0 239 1.007452e-31
## 2 3.780745e-24 0 0 230 2.217275e-31
## AssumedDissociationMethod IsotopeError isDecoy post pre end start accession
## 1 CID 0 FALSE A K 283 249 CE02347
## 2 CID 0 FALSE A K 182 142 CE07055
## length
## 1 393
## 2 206
## description
## 1 WBGene00001993; locus:hpd-1; 4-hydroxyphenylpyruvate dioxygenase; status:Confirmed; UniProt:Q22633; protein_id:CAA90315.1; T21C12.2
## 2 WBGene00001755; locus:gst-7; glutathione S-transferase; status:Confirmed; UniProt:P91253; protein_id:AAB37846.1; F11G11.2
## pepSeq modified modification
## 1 AISQIQEYVDYYGGSGVQHIALNTSDIITAIEALR FALSE <NA>
## 2 SAGSGYLVGDSLTFVDLLVAQHTADLLAANAALLDEFPQFK FALSE <NA>
## idFile spectrumFile
## 1 c_elegans.mzid.gz c_elegans_A_3_1_21Apr10_Draco_10-03-04_dta.txt
## 2 c_elegans.mzid.gz c_elegans_A_3_1_21Apr10_Draco_10-03-04_dta.txt
## databaseFile peptide
## 1 ID_004174_E48C5B52.fasta K.AISQIQEYVDYYGGSGVQHIALNTSDIITAIEALR.A
## 2 ID_004174_E48C5B52.fasta K.SAGSGYLVGDSLTFVDLLVAQHTADLLAANAALLDEFPQFK.A
## numIrregCleavages numMissCleavages msmsScore absParentMassErrorPPM
## 1 0 0 30.99678 0.3843772
## 2 0 0 30.65418 1.3689451
## [ reached 'max' / getOption("max.print") -- omitted 4 rows ]Page built: 2021-03-17