Chapter 4 Unsupervised Learning
4.1 Introduction
In unsupervised learning (UML), no labels are provided, and the learning algorithm focuses solely on detecting structure in unlabelled input data. One generally differentiates between
Clustering, where the goal is to find homogeneous subgroups within the data; the grouping is based on distance between observations.
Dimensionality reduction, where the goal is to identify patterns in the features of the data. Dimensionality reduction is often used to facilitate visualisation of the data, as well as a pre-processing method before supervised learning.
UML presents specific challenges and benefits:
- there is no single goal in UML
- there is generally much more unlabelled data available than labelled data.
4.2 k-means clustering
The k-means clustering algorithms aims at partitioning n observations into a fixed number of k clusters. The algorithm will find homogeneous clusters.
In R, we use
where
xis a numeric data matrixcentersis the pre-defined number of clusters- the k-means algorithm has a random component and can be repeated
nstarttimes to improve the returned model
Challenge:
- To learn about k-means, let’s use the
irisdataset with the sepal and petal length variables only (to facilitate visualisation). Create such a data matrix and name itx
- Run the k-means algorithm on the newly generated data
x, save the results in a new variablecl, and explore its output when printed.
- The actual results of the algorithms, i.e. the cluster membership can be accessed in the
clusterselement of the clustering result output. Use it to colour the inferred clusters to generate a figure like that shown below.
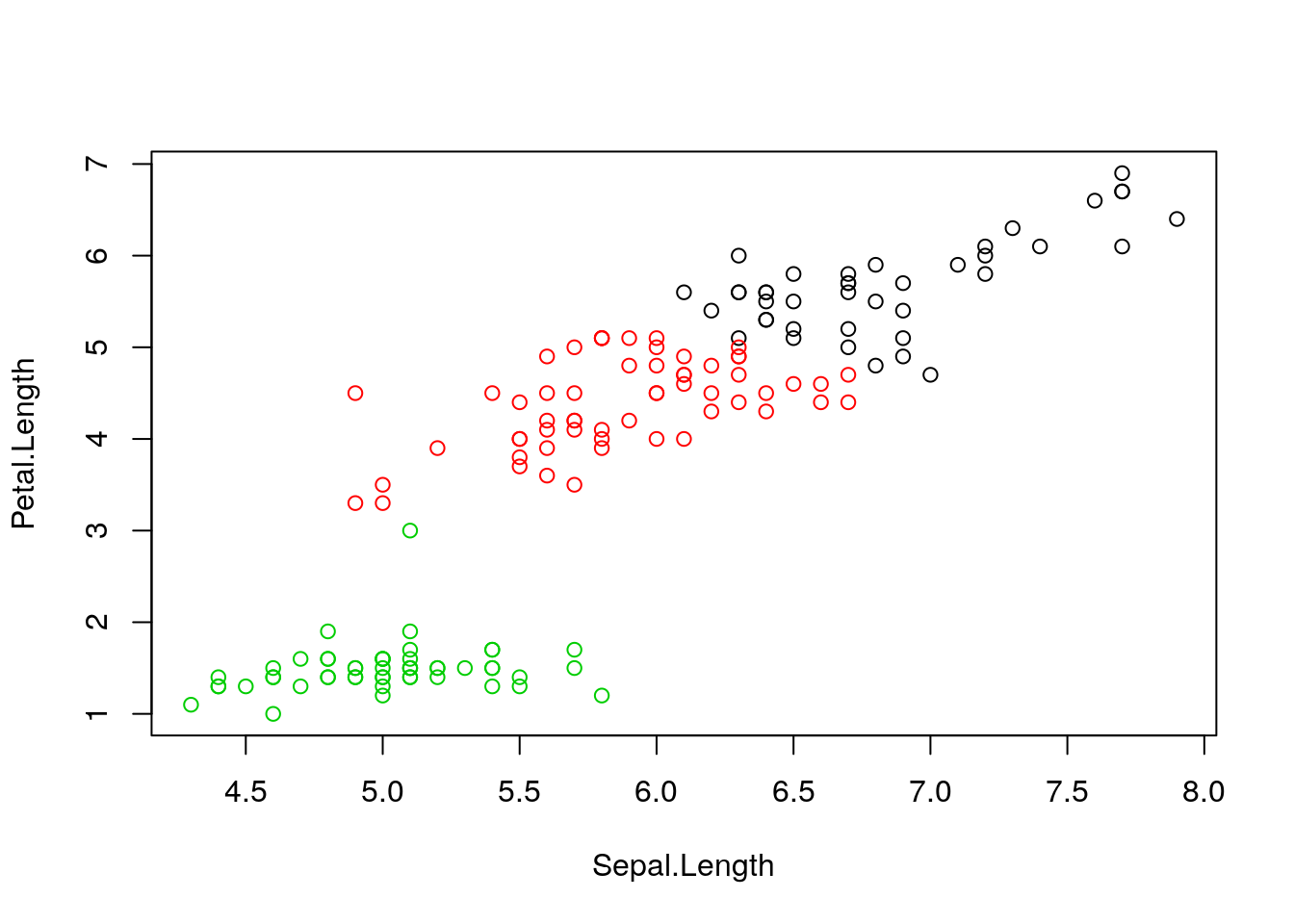
Figure 4.1: k-means algorithm on sepal and petal lengths
4.2.1 How does k-means work
Initialisation: randomly assign class membership
Figure 4.2: k-means random intialisation
Iteration:
- Calculate the centre of each subgroup as the average position of all observations is that subgroup.
- Each observation is then assigned to the group of its nearest centre.
It’s also possible to stop the algorithm after a certain number of iterations, or once the centres move less than a certain distance.
par(mfrow = c(1, 2))
plot(x, col = init)
centres <- sapply(1:3, function(i) colMeans(x[init == i, ], ))
centres <- t(centres)
points(centres[, 1], centres[, 2], pch = 19, col = 1:3)
tmp <- dist(rbind(centres, x))
tmp <- as.matrix(tmp)[, 1:3]
ki <- apply(tmp, 1, which.min)
ki <- ki[-(1:3)]
plot(x, col = ki)
points(centres[, 1], centres[, 2], pch = 19, col = 1:3)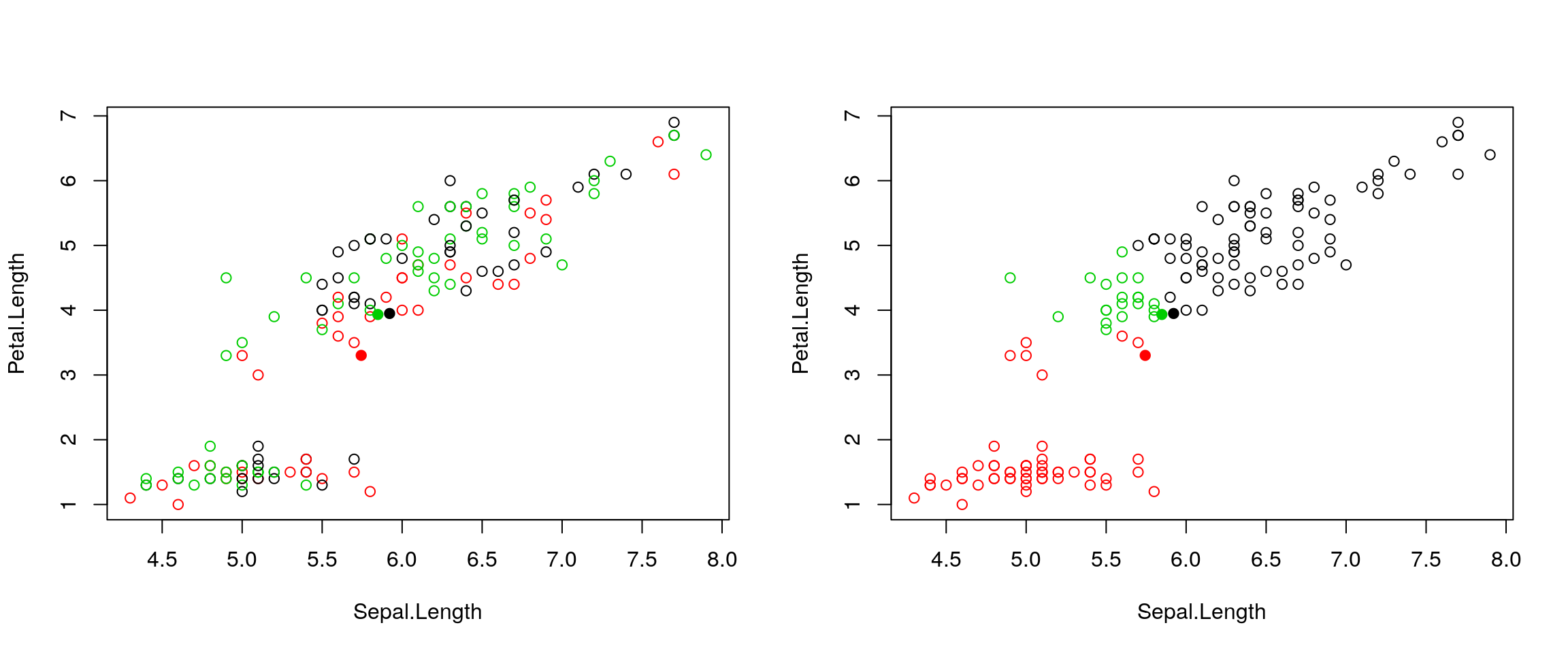
Figure 4.3: k-means iteration: calculate centers (left) and assign new cluster membership (right)
Termination: Repeat iteration until no point changes its cluster membership.

k-means convergence (credit Wikipedia)
4.2.2 Model selection
Due to the random initialisation, one can obtain different clustering results. When k-means is run multiple times, the best outcome, i.e. the one that generates the smallest total within cluster sum of squares (SS), is selected. The total within SS is calculated as:
For each cluster results:
- for each observation, determine the squared euclidean distance from observation to centre of cluster
- sum all distances
Note that this is a local minimum; there is no guarantee to obtain a global minimum.
Challenge:
Repeat k-means on our
xdata multiple times, setting the number of iterations to 1 or greater and check whether you repeatedly obtain the same results. Try the same with random data of identical dimensions.
cl1 <- kmeans(x, centers = 3, nstart = 10)
cl2 <- kmeans(x, centers = 3, nstart = 10)
table(cl1$cluster, cl2$cluster)##
## 1 2 3
## 1 0 41 0
## 2 51 0 0
## 3 0 0 58cl1 <- kmeans(x, centers = 3, nstart = 1)
cl2 <- kmeans(x, centers = 3, nstart = 1)
table(cl1$cluster, cl2$cluster)##
## 1 2 3
## 1 41 0 0
## 2 0 0 58
## 3 0 51 0set.seed(42)
xr <- matrix(rnorm(prod(dim(x))), ncol = ncol(x))
cl1 <- kmeans(xr, centers = 3, nstart = 1)
cl2 <- kmeans(xr, centers = 3, nstart = 1)
table(cl1$cluster, cl2$cluster)##
## 1 2 3
## 1 0 52 0
## 2 0 0 46
## 3 52 0 0diffres <- cl1$cluster != cl2$cluster
par(mfrow = c(1, 2))
plot(xr, col = cl1$cluster, pch = ifelse(diffres, 19, 1))
plot(xr, col = cl2$cluster, pch = ifelse(diffres, 19, 1))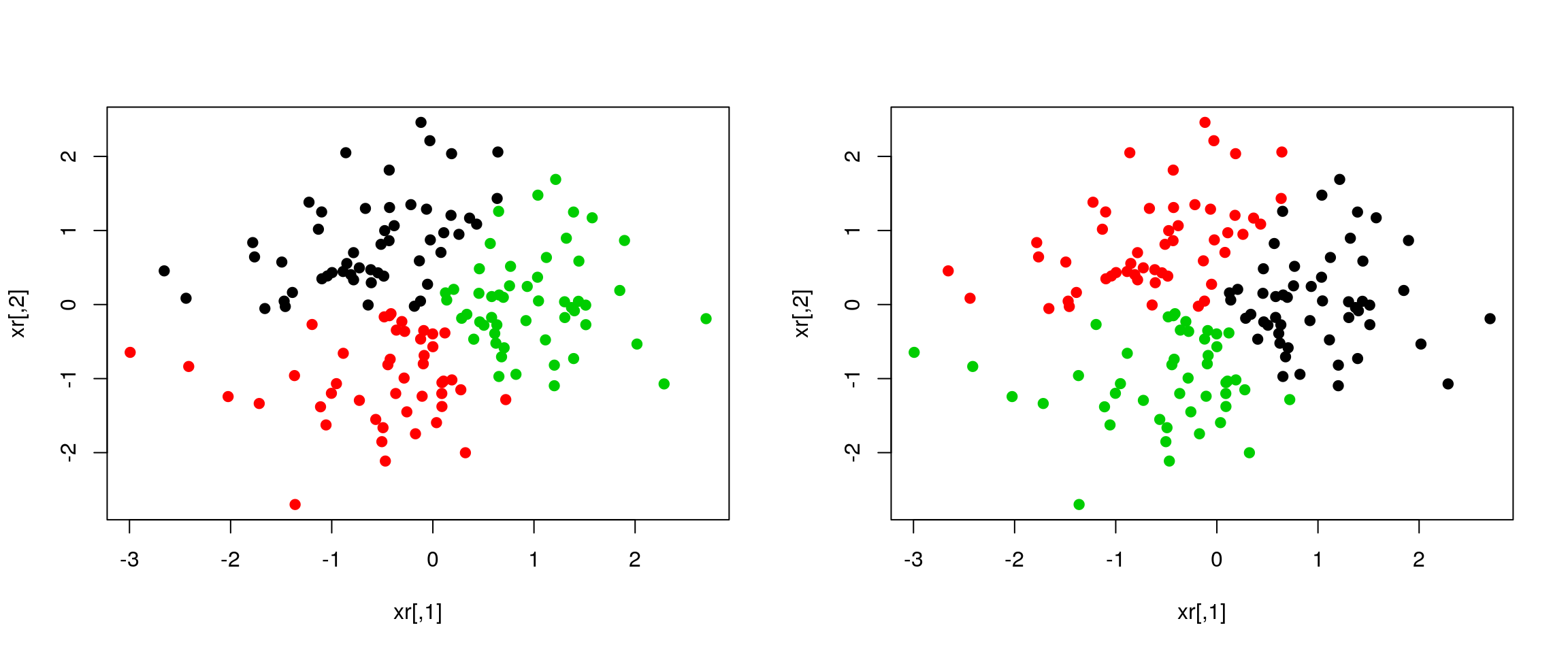
Figure 4.4: Different k-means results on the same (random) data
4.2.3 How to determine the number of clusters
- Run k-means with
k=1,k=2, …,k=n - Record total within SS for each value of k.
- Choose k at the elbow position, as illustrated below.
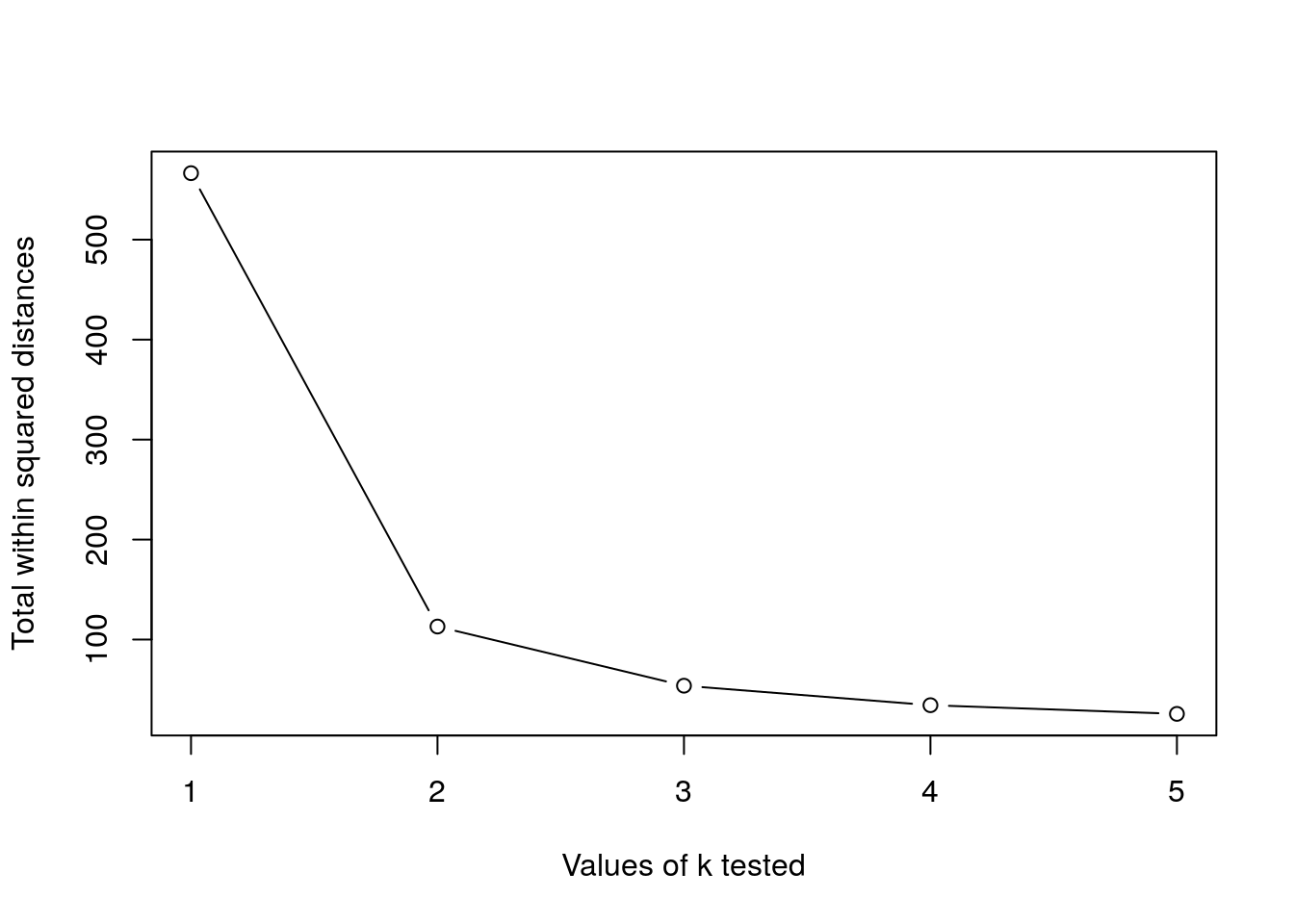
Challenge
Calculate the total within sum of squares for k from 1 to 5 for our
xtest data, and reproduce the figure above.
4.3 Hierarchical clustering
4.3.1 How does hierarchical clustering work
Initialisation: Starts by assigning each of the n points its own cluster
Iteration
- Find the two nearest clusters, and join them together, leading to n-1 clusters
- Continue the cluster merging process until all are grouped into a single cluster
Termination: All observations are grouped within a single cluster.
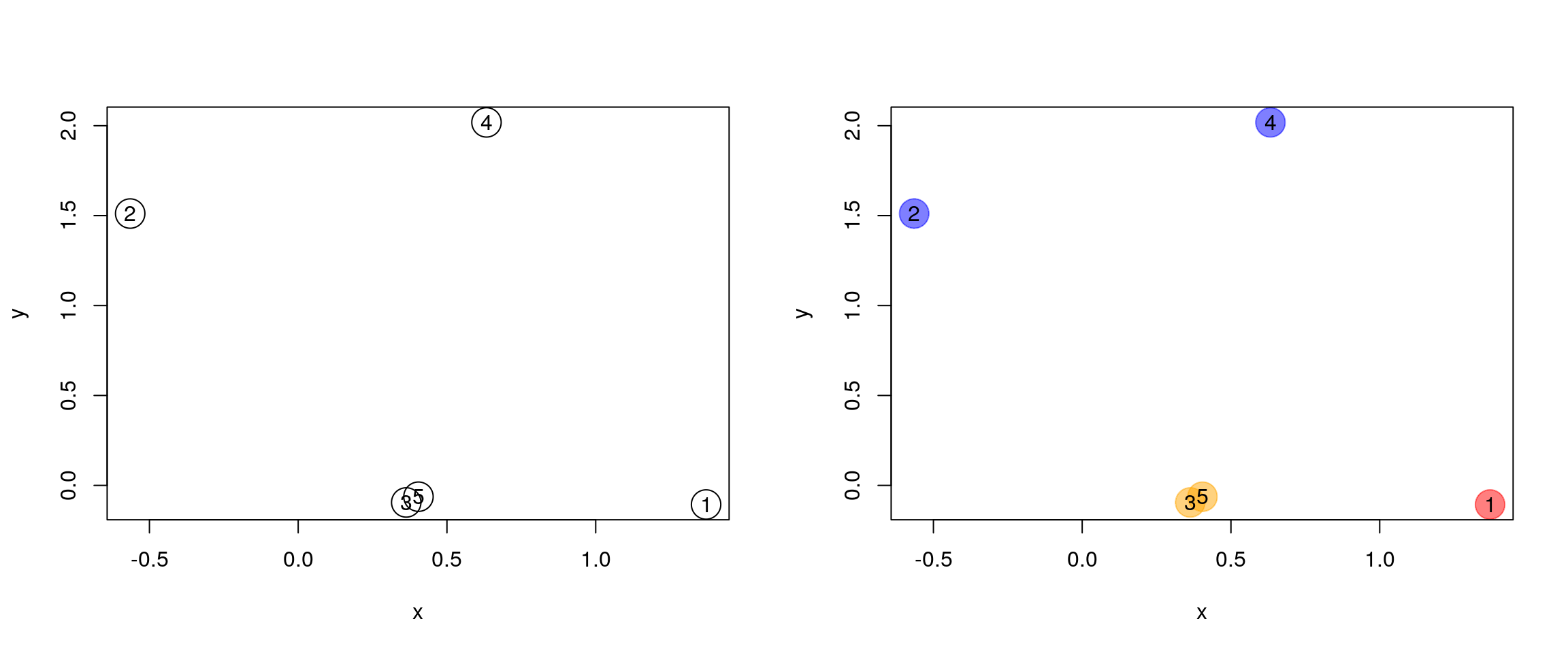
Figure 4.5: Hierarchical clustering: initialisation (left) and colour-coded results after iteration (right).
The results of hierarchical clustering are typically visualised along a dendrogram, where the distance between the clusters is proportional to the branch lengths.
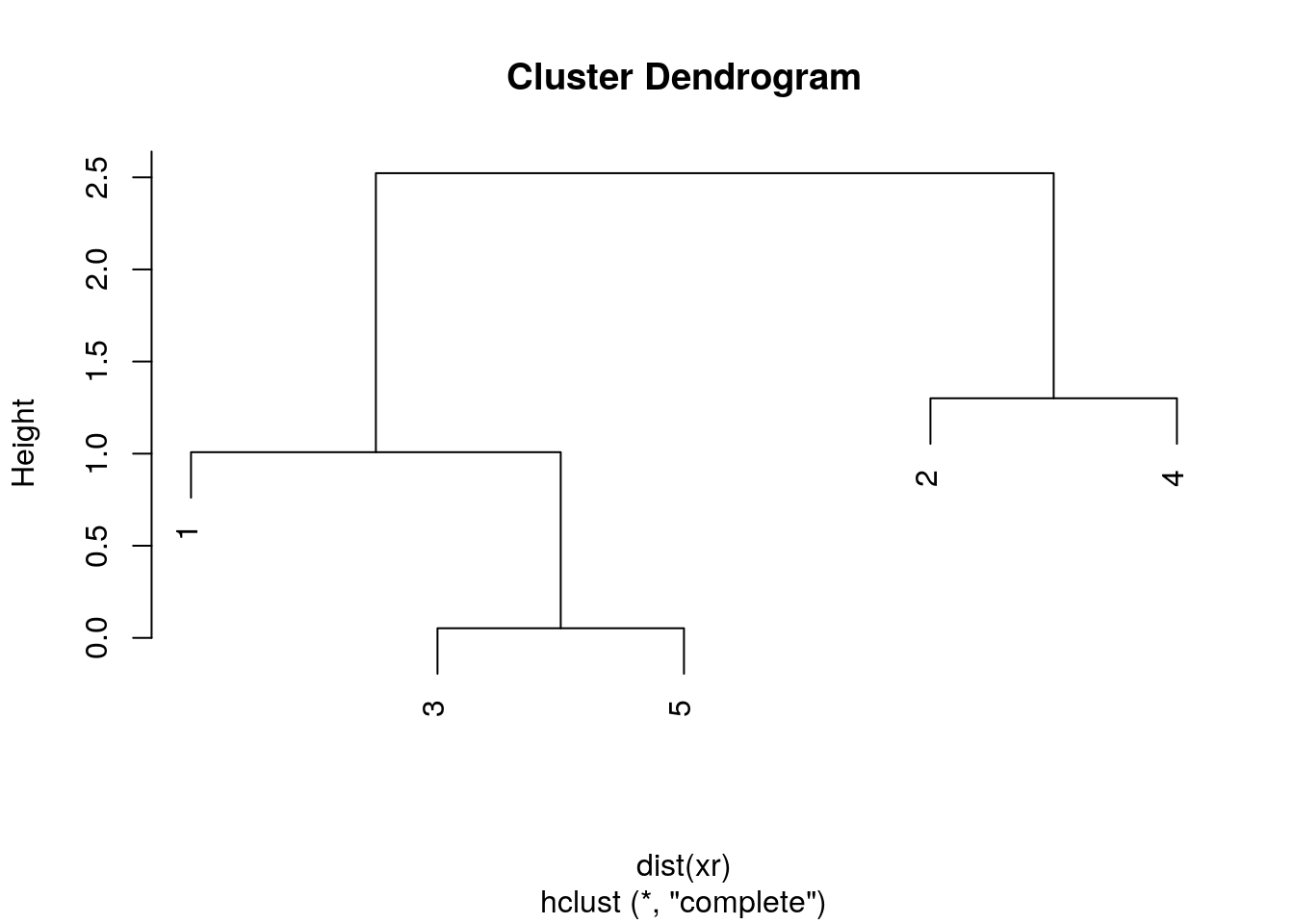
Figure 4.6: Visualisation of the hierarchical clustering results on a dendrogram
In R:
- Calculate the distance using
dist, typically the Euclidean distance. - Hierarchical clustering on this distance matrix using
hclust
Challenge
Apply hierarchical clustering on the
irisdata and generate a dendrogram using the dedicatedplotmethod.
##
## Call:
## hclust(d = d)
##
## Cluster method : complete
## Distance : euclidean
## Number of objects: 150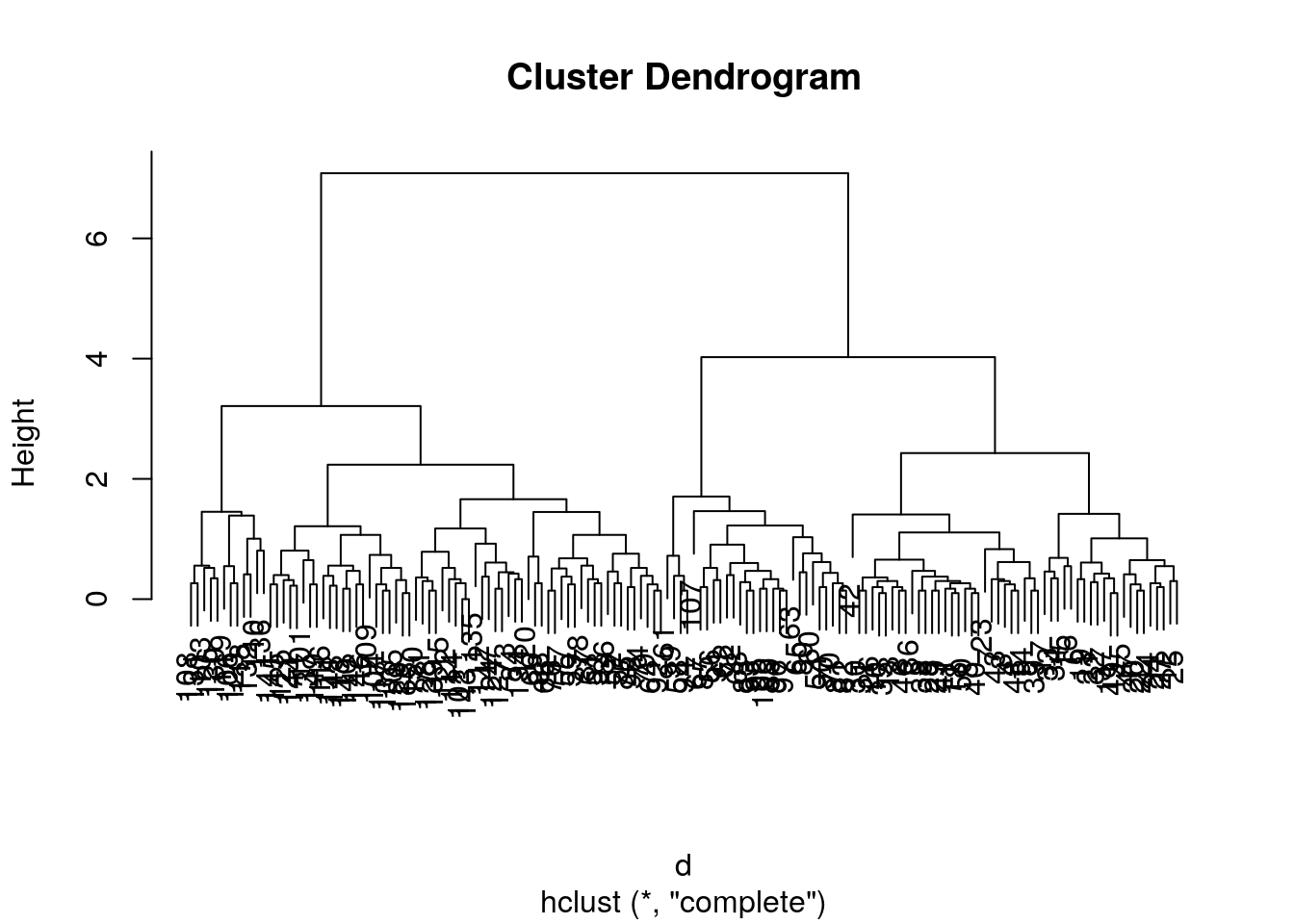
4.3.2 Defining clusters
After producing the hierarchical clustering result, we need to cut the tree (dendrogram) at a specific height to defined the clusters. For example, on our test dataset above, we could decide to cut it at a distance around 1.5, with would produce 2 clusters.
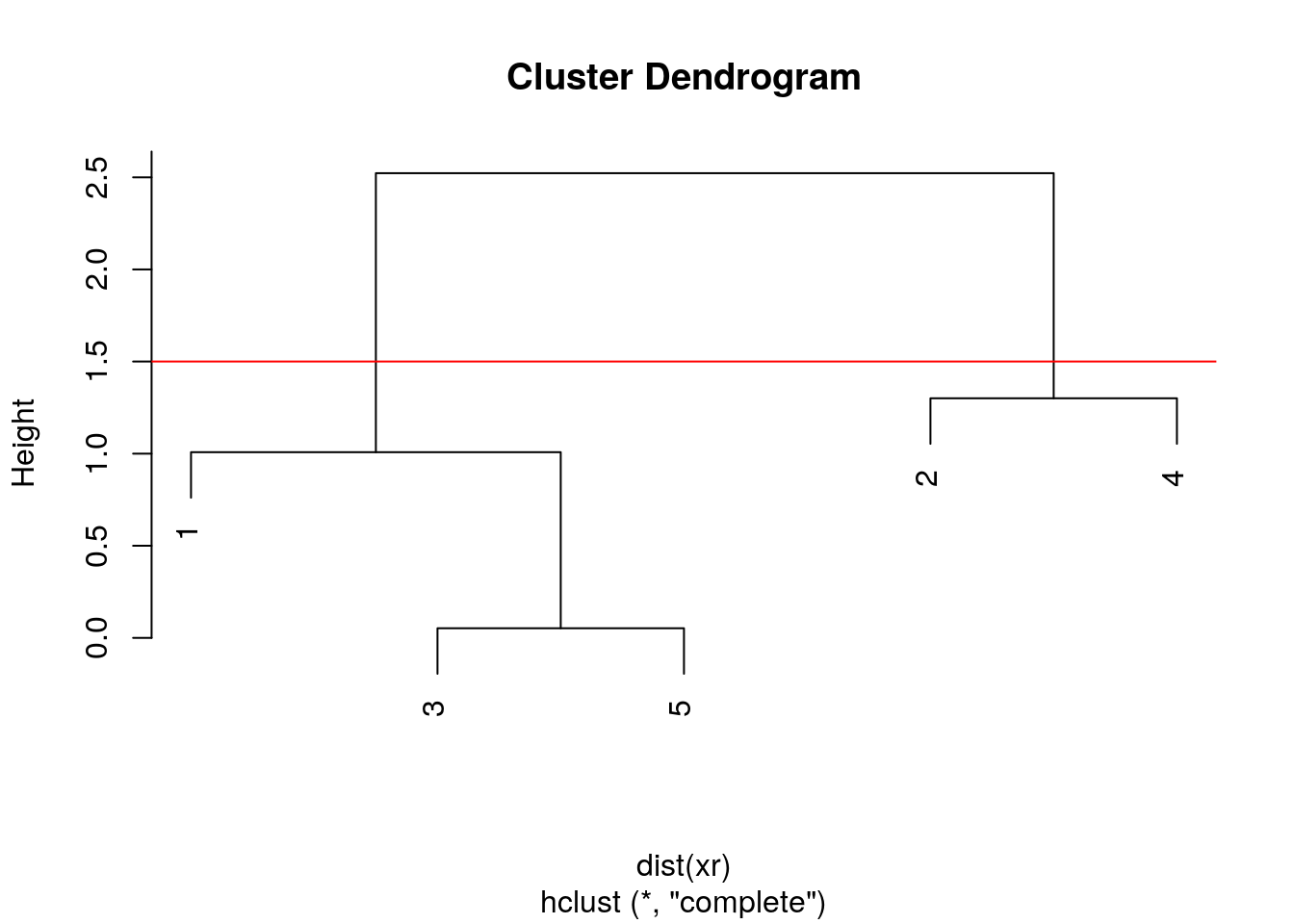
Figure 4.7: Cutting the dendrogram at height 1.5.
In R we can us the cutree function to
- cut the tree at a specific height:
cutree(hcl, h = 1.5) - cut the tree to get a certain number of clusters:
cutree(hcl, k = 2)
Challenge
- Cut the iris hierarchical clustering result at a height to obtain 3 clusters by setting
h.- Cut the iris hierarchical clustering result at a height to obtain 3 clusters by setting directly
k, and verify that both provide the same results.
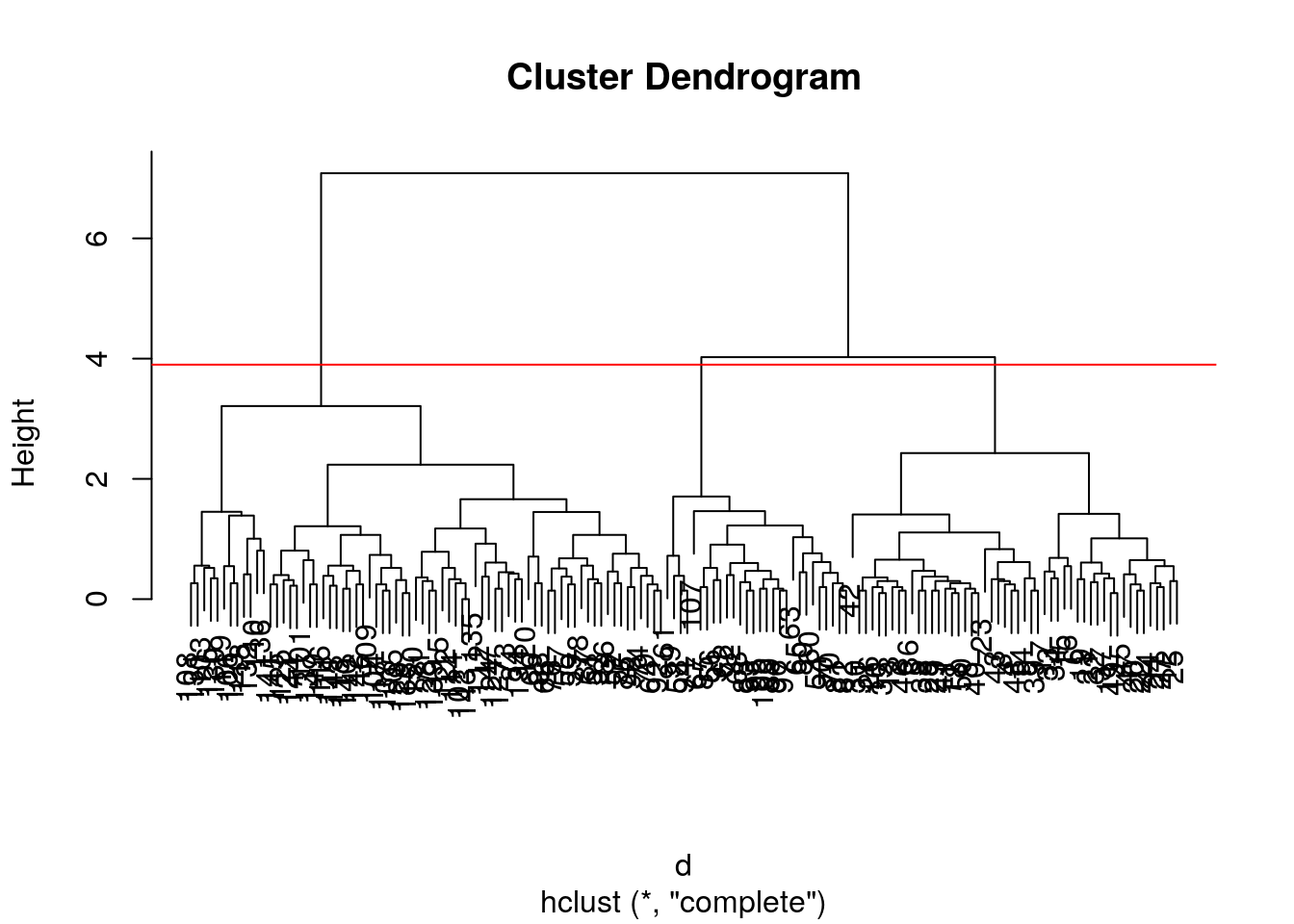
## [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [38] 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 3 2 3 2 3 2 3 3 3 3 2 3 2 3 3 2 3 2 3 2 2
## [75] 2 2 2 2 2 3 3 3 3 2 3 2 2 2 3 3 3 2 3 3 3 3 3 2 3 3 2 2 2 2 2 2 3 2 2 2 2
## [112] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
## [149] 2 2## [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [38] 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 3 2 3 2 3 2 3 3 3 3 2 3 2 3 3 2 3 2 3 2 2
## [75] 2 2 2 2 2 3 3 3 3 2 3 2 2 2 3 3 3 2 3 3 3 3 3 2 3 3 2 2 2 2 2 2 3 2 2 2 2
## [112] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
## [149] 2 2## [1] TRUEChallenge
Using the same value
k = 3, verify if k-means and hierarchical clustering produce the same results on theirisdata.Which one, if any, is correct?
km <- kmeans(iris[, 1:4], centers = 3, nstart = 10)
hcl <- hclust(dist(iris[, 1:4]))
table(km$cluster, cutree(hcl, k = 3))##
## 1 2 3
## 1 0 34 28
## 2 0 38 0
## 3 50 0 0par(mfrow = c(1, 2))
plot(iris$Petal.Length, iris$Sepal.Length, col = km$cluster, main = "k-means")
plot(iris$Petal.Length, iris$Sepal.Length, col = cutree(hcl, k = 3), main = "Hierarchical clustering")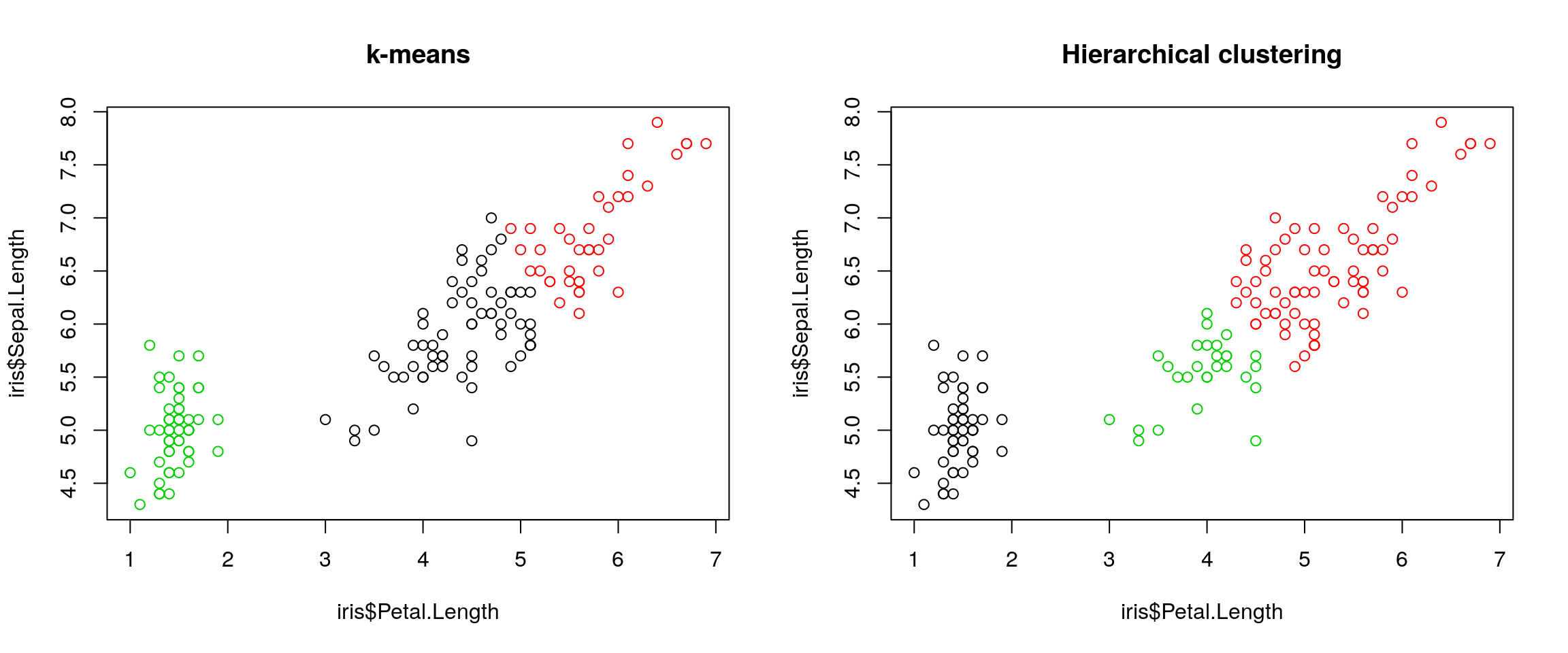
##
## 1 2 3
## setosa 0 0 50
## versicolor 48 2 0
## virginica 14 36 0##
## 1 2 3
## setosa 50 0 0
## versicolor 0 23 27
## virginica 0 49 14.4 Pre-processing
Many of the machine learning methods that are regularly used are sensitive to difference scales. This applies to unsupervised methods as well as supervised methods, as we will see in the next chapter.
A typical way to pre-process the data prior to learning is to scale the data, or apply principal component analysis (next section). Scaling assures that all data columns have a mean of 0 and standard deviation of 1.
In R, scaling is done with the scale function.
Challenge
Using the
mtcarsdata as an example, verify that the variables are of different scales, then scale the data. To observe the effect different scales, compare the hierarchical clusters obtained on the original and scaled data.
## mpg cyl disp hp drat wt qsec
## 20.090625 6.187500 230.721875 146.687500 3.596563 3.217250 17.848750
## vs am gear carb
## 0.437500 0.406250 3.687500 2.812500hcl1 <- hclust(dist(mtcars))
hcl2 <- hclust(dist(scale(mtcars)))
par(mfrow = c(1, 2))
plot(hcl1, main = "original data")
plot(hcl2, main = "scaled data")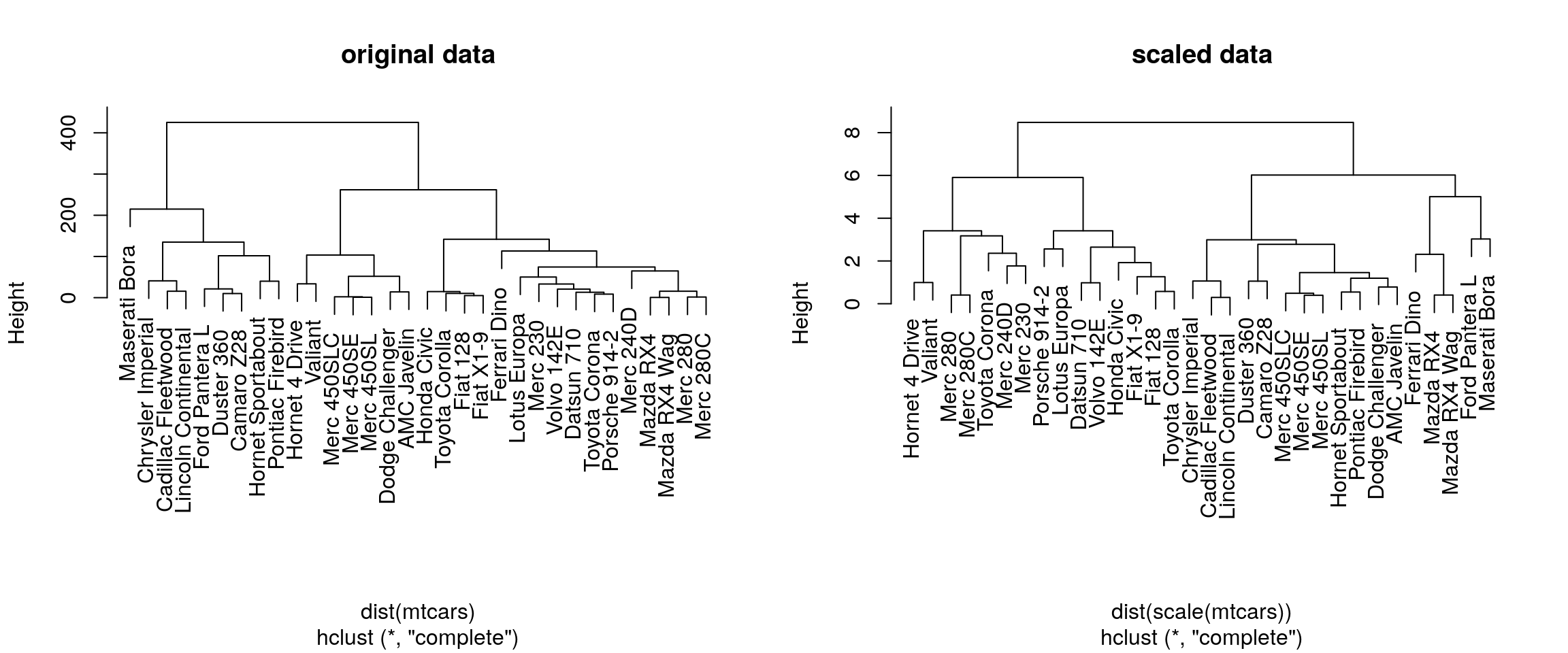
4.5 Principal component analysis (PCA)
Dimensionality reduction techniques are widely used and versatile techniques that can be used to:
- find structure in features
- pre-processing for other ML algorithms, and
- aid in visualisation.
The basic principle of dimensionality reduction techniques is to transform the data into a new space that summarise properties of the whole data set along a reduced number of dimensions. These are then ideal candidates used to visualise the data along these reduced number of informative dimensions.
4.5.1 How does it work
Principal Component Analysis (PCA) is a technique that transforms the original n-dimensional data into a new n-dimensional space.
- These new dimensions are linear combinations of the original data, i.e. they are composed of proportions of the original variables.
- Along these new dimensions, called principal components, the data expresses most of its variability along the first PC, then second, …
- Principal components are orthogonal to each other, i.e. non-correlated.
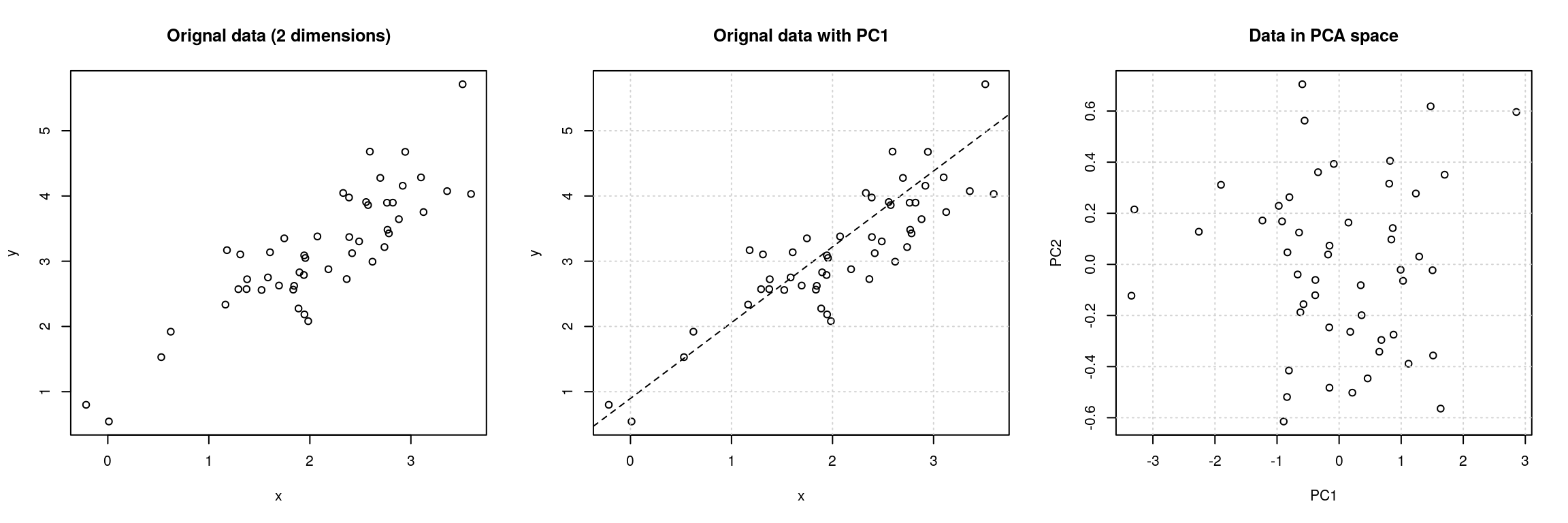
Figure 4.8: Original data (left). PC1 will maximise the variability while minimising the residuals (centre). PC2 is orthogonal to PC1 (right).
In R, we can use the prcomp function.
Let’s explore PCA on the iris data. While it contains only 4
variables, is already becomes difficult to visualise the 3 groups
along all these dimensions.
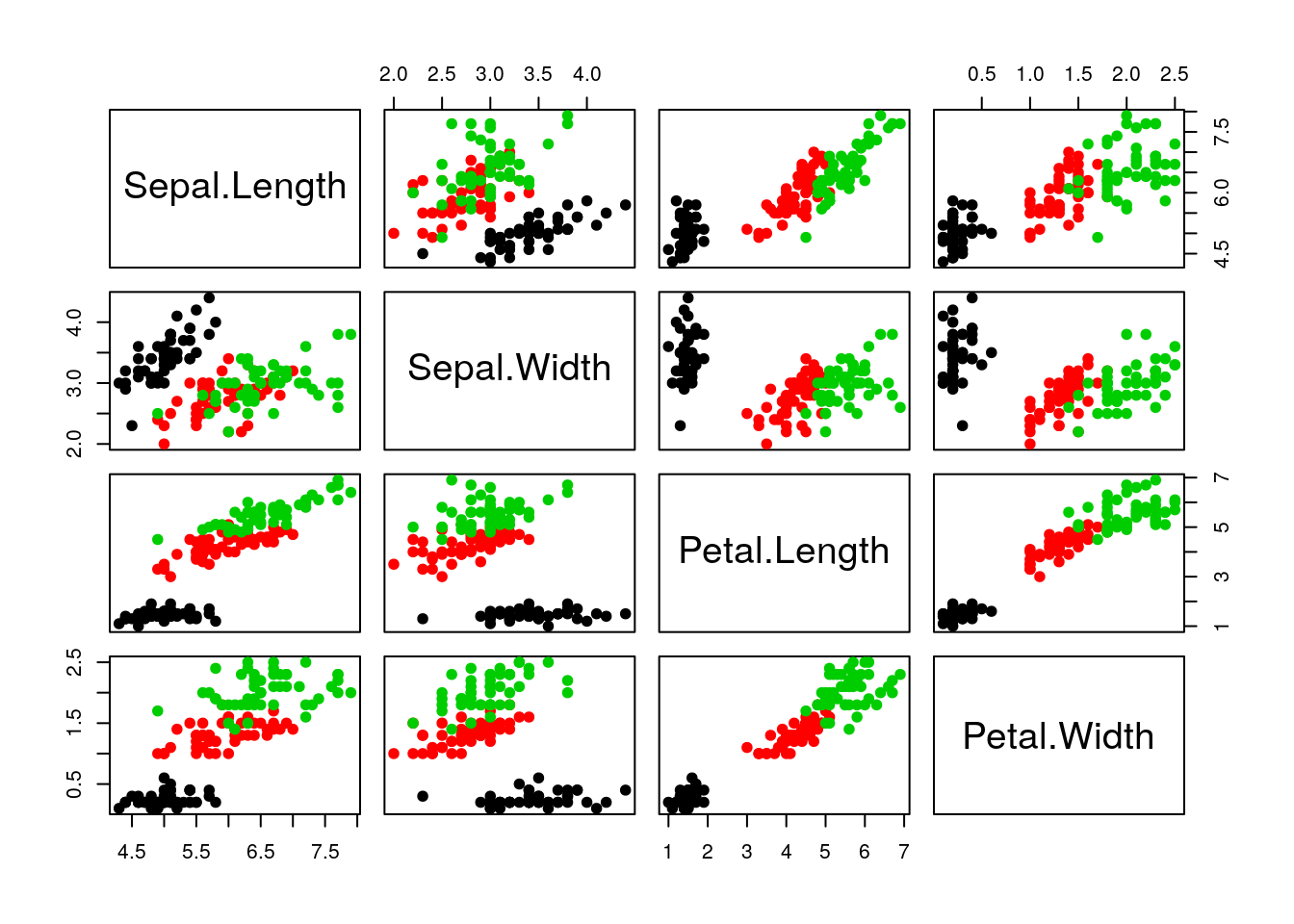
Let’s use PCA to reduce the dimension.
## Importance of components:
## PC1 PC2 PC3 PC4
## Standard deviation 2.0563 0.49262 0.2797 0.15439
## Proportion of Variance 0.9246 0.05307 0.0171 0.00521
## Cumulative Proportion 0.9246 0.97769 0.9948 1.00000A summary of the prcomp output shows that along PC1 along, we are
able to retain over 92% of the total variability in the data.
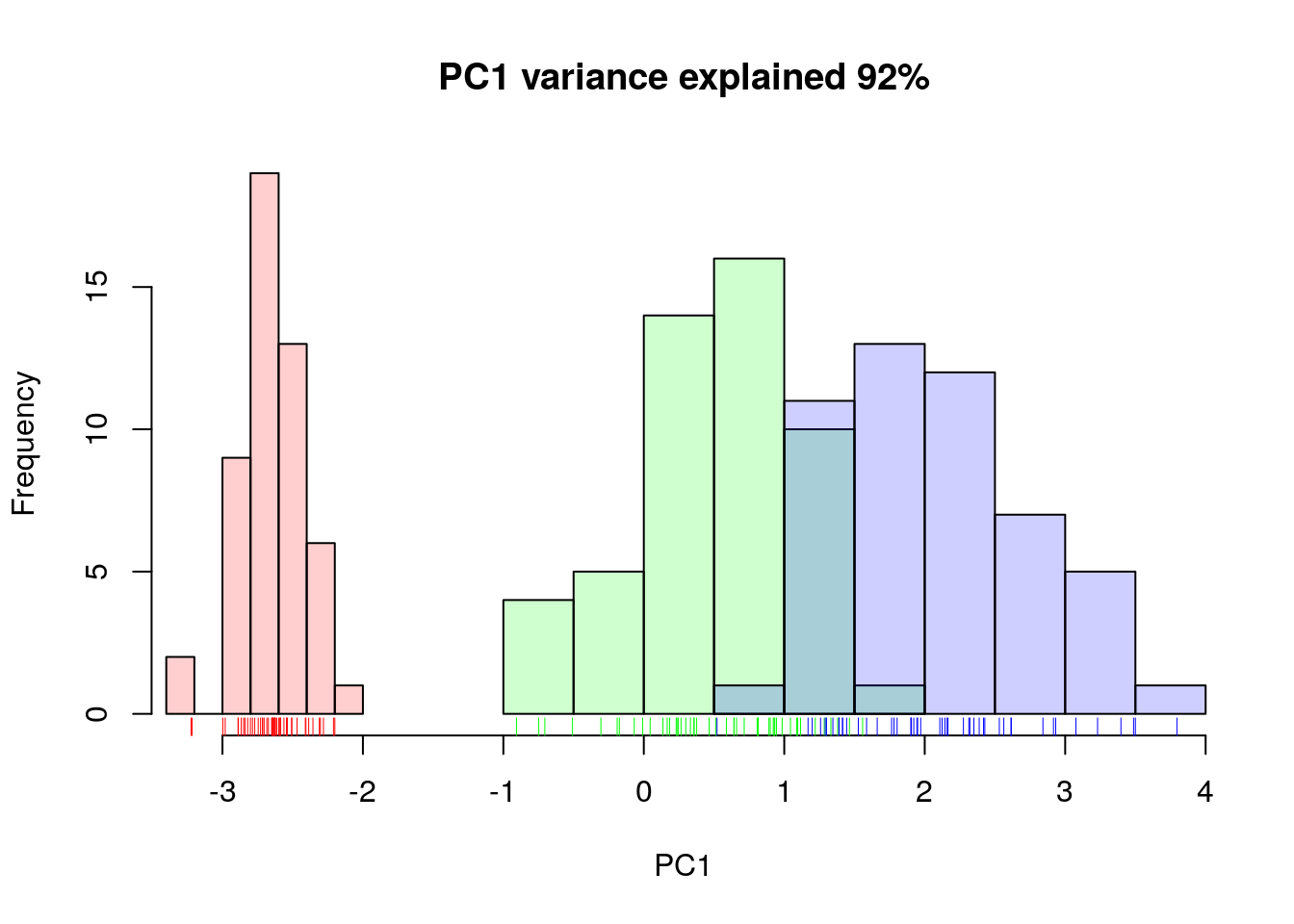
Figure 4.9: Iris data along PC1.
4.5.2 Visualisation
A biplot features all original points re-mapped (rotated) along the first two PCs as well as the original features as vectors along the same PCs. Feature vectors that are in the same direction in PC space are also correlated in the original data space.
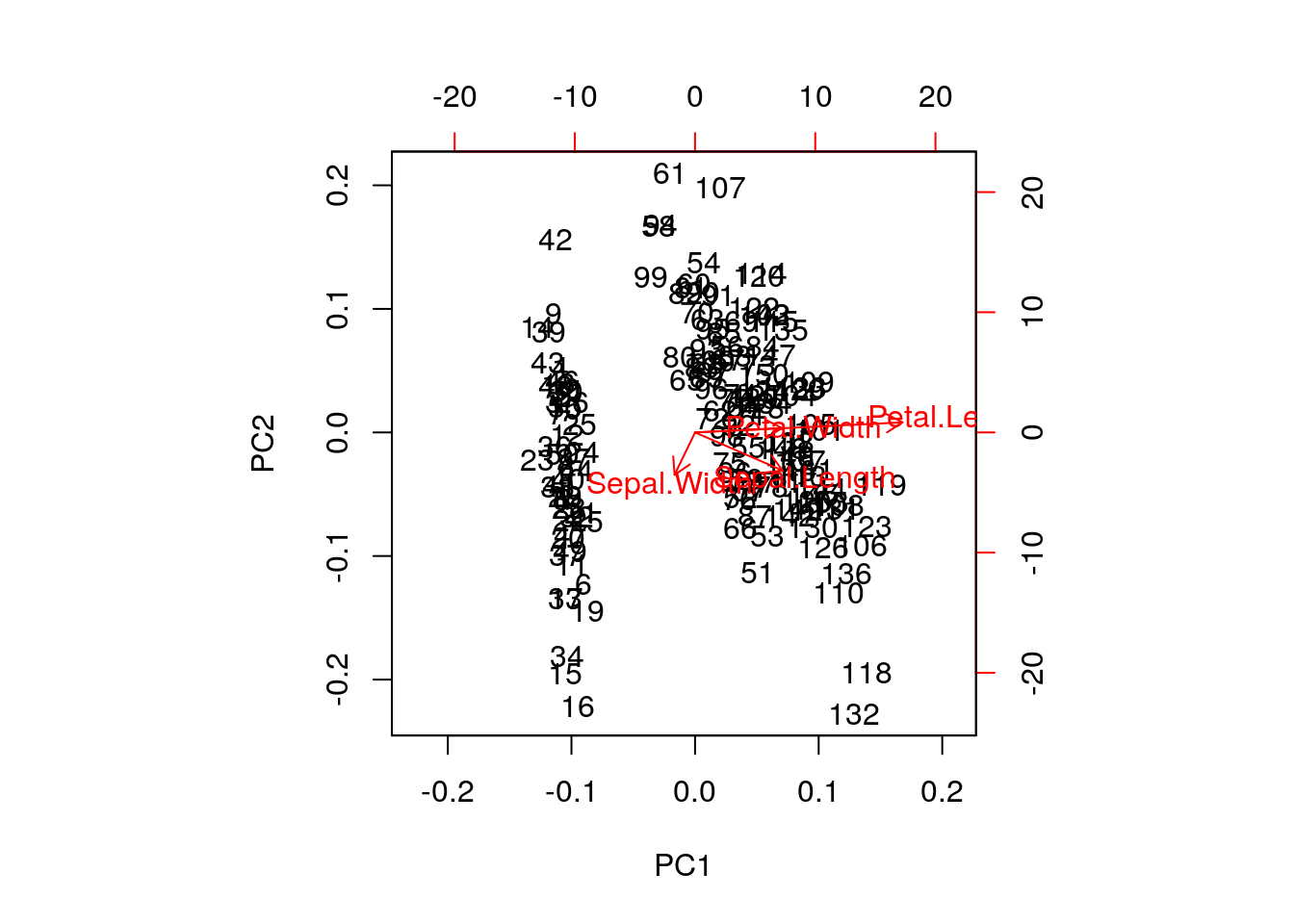
One important piece of information when using PCA is the proportion of variance explained along the PCs, in particular when dealing with high dimensional data, as PC1 and PC2 (that are generally used for visualisation), might only account for an insufficient proportion of variance to be relevant on their own.
In the code chunk below, I extract the standard deviations from the PCA result to calculate the variances, then obtain the percentage of and cumulative variance along the PCs.
## [1] 0.924618723 0.053066483 0.017102610 0.005212184## [1] 0.9246187 0.9776852 0.9947878 1.0000000Challenge
- Repeat the PCA analysis on the iris dataset above, reproducing the biplot and preparing a barplot of the percentage of variance explained by each PC.
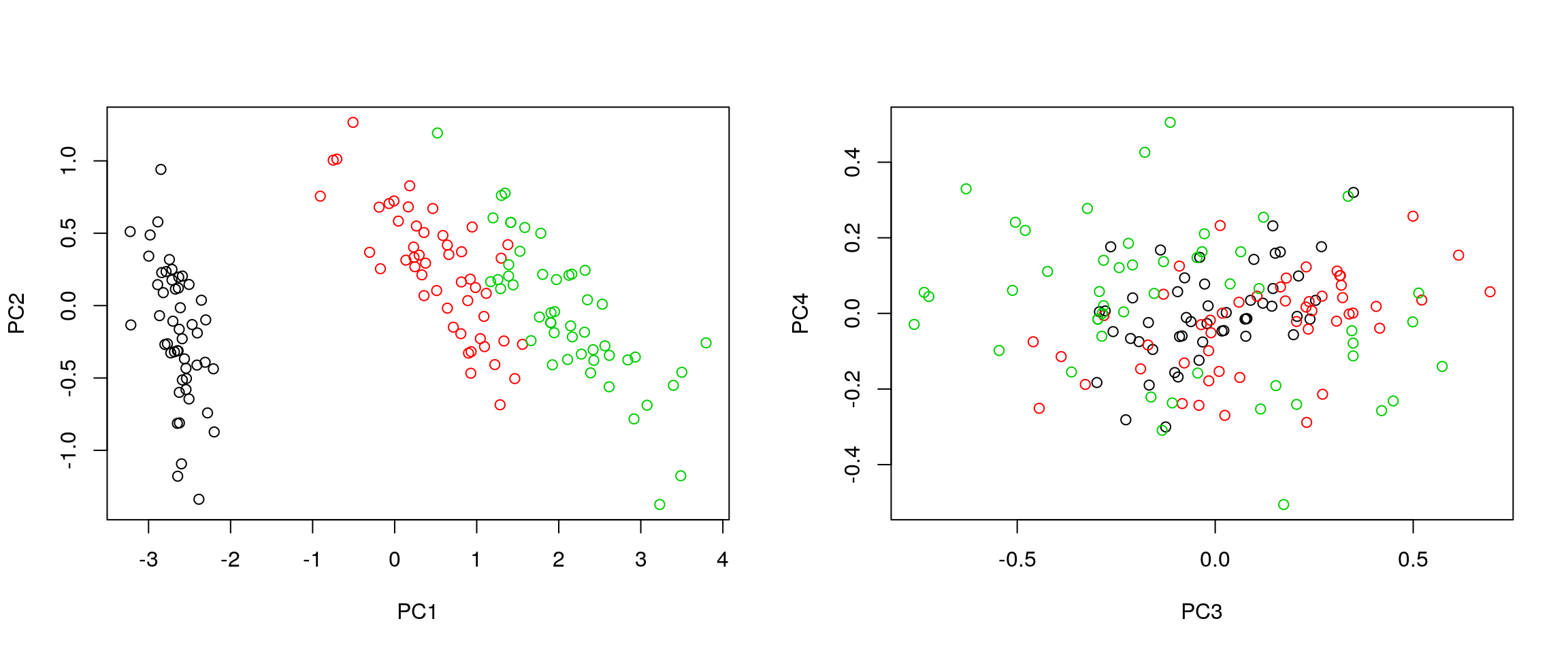
- It is often useful to produce custom figures using the data coordinates in PCA space, which can be accessed as
xin theprcompobject. Reproduce the PCA plots below, along PC1 and PC2 and PC3 and PC4 respectively.
4.5.3 Data pre-processing
We haven’t looked at other prcomp parameters, other that the first
one, x. There are two other ones that are or importance, in
particular in the light of the section on pre-processing above, which
are center and scale.. The former is set to TRUE by default,
while the second one is set the FALSE.
Challenge
Repeat the analysis comparing the need for scaling on the
mtcarsdataset, but using PCA instead of hierarchical clustering. When comparing the two.
par(mfrow = c(1, 2))
biplot(prcomp(mtcars, scale = FALSE), main = "No scaling") ## 1
biplot(prcomp(mtcars, scale = TRUE), main = "With scaling") ## 2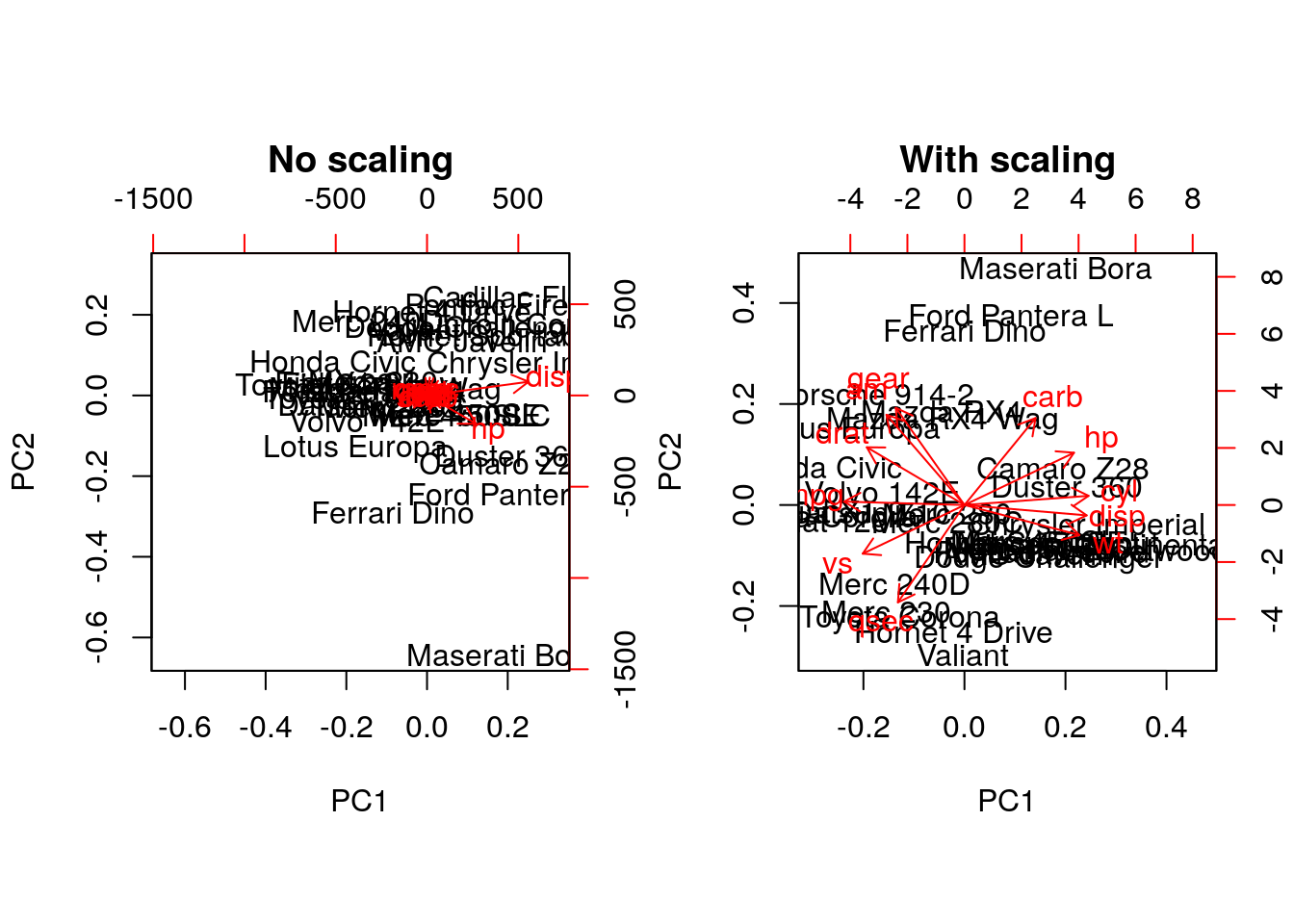
disp and hp are the features with the highest
loadings along PC1 and 2 (all others are negligible), which are also
those with the highest units of measurement. Scaling removes this
effect.
4.5.4 Final comments on PCA
Real datasets often come with missing values. In R, these should
be encoded using NA. Unfortunately, PCA cannot deal with missing
values, and observations containing NA values will be dropped
automatically. This is a viable solution only when the proportion of
missing values is low.
It is also possible to impute missing values. This is described in greater details in the Data pre-processing section in the supervised machine learning chapter.
Finally, we should be careful when using categorical data in any of
the unsupervised methods described above. Categories are generally
represented as factors, which are encoded as integer levels, and might
give the impression that a distance between levels is a relevant
measure (which it is not, unless the factors are ordered). In such
situations, categorical data can be dropped, or it is possible to
encode categories as binary dummy variables. For example, if we
have 3 categories, say A, B and C, we would create two dummy
variables to encode the categories as:
| x | y | |
|---|---|---|
| A | 1 | 0 |
| B | 0 | 1 |
| C | 0 | 0 |
so that the distance between each category are approximately equal to 1.
4.6 t-Distributed Stochastic Neighbour Embedding
t-Distributed Stochastic Neighbour Embedding (t-SNE) is a non-linear dimensionality reduction technique, i.e. that different regions of the data space will be subjected to different transformations. t-SNE will compress small distances, thus bringing close neighbours together, and will ignore large distances. It is particularly well suited for very high dimensional data.
In R, we can use the Rtsne function from the Rtsne.
Before, we however need to remove any duplicated entries in the
dataset.
library("Rtsne")
uiris <- unique(iris[, 1:5])
iristsne <- Rtsne(uiris[, 1:4])
plot(iristsne$Y, col = uiris$Species)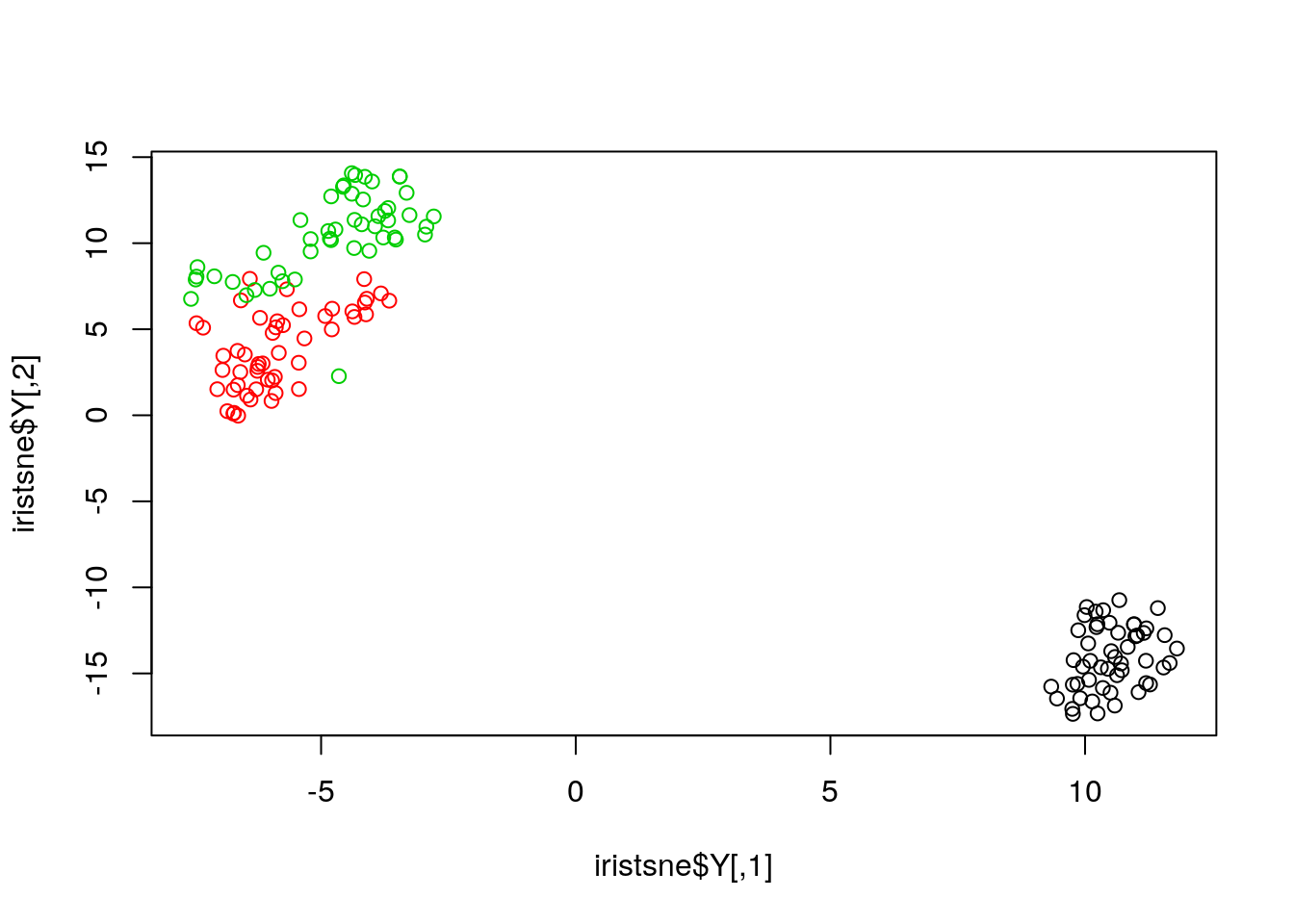
As with PCA, the data can be scaled and centred prior the running
t-SNE (see the pca_center and pca_scale arguments). The algorithm
is stochastic, and will produce different results at each repetition.
4.6.1 Parameter tuning
t-SNE (as well as many other methods, in particular classification algorithms) has two important parameters that can substantially influence the clustering of the data
- Perplexity: balances global and local aspects of the data.
- Iterations: number of iterations before the clustering is stopped.
It is important to adapt these for different data. The figure below shows a 5032 by 20 dataset that represent protein sub-cellular localisation.
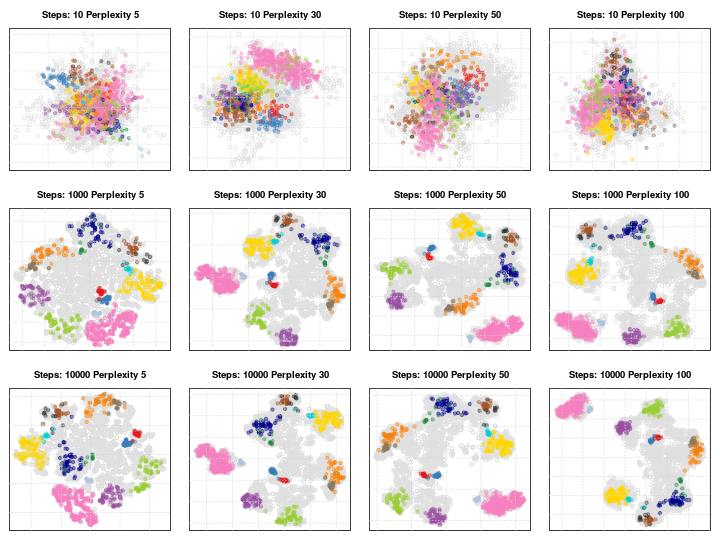
Effect of different perplexity and iterations when running t-SNE
As a comparison, below are the same data with PCA (left) and t-SNE (right).
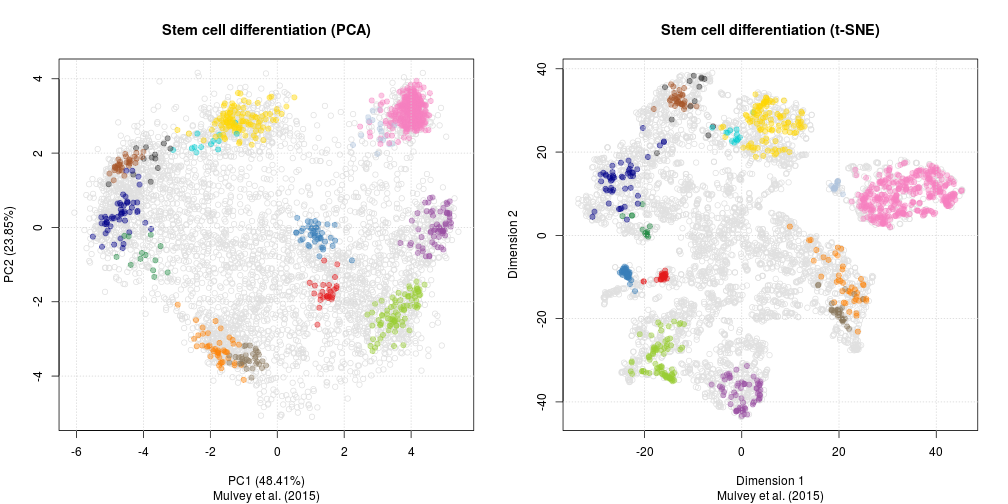
PCA and t-SNE on hyperLOPIT