
How to Manage Data: Data Stewardship and FAIR Skills
In this interactive talk at the Hong Kong University of Science and Technology Research Data Management Symposium 2021, Laurent Gatto and Marta Teperek will join forces to offer some concrete examples on improving research reproducibility and transparency. Laurent will speak from his own perspective as a researcher and will share some tips and tricks on how one can become a better scientist by applying open and reproducible research practices. Marta will speak from the perspective of support staff and will offer several examples of how institutions can partner with researchers to help make research more reproducible and more transparent.
In our talk we will cover aspects such as people support, policies, training, rewards and community building. The common theme will be collaboration and partnership between researchers and support staff.
We promise a lot of concrete examples and interaction, and plenty of time for questions!
The slides are available here at bit.ly/202110RDM.
What it’s really about
The actual title of this talk comes in two parts:
Becoming a better scientist with open and reproducible research and supporting the scientist on this journey.
and
Or… the importance of collaboration between researchers and support staff for sustainable open and reproducible research practices.
The goal is to have a joint seminar, is to mix some of Laurent’s experiences as an open researcher/teacher and Marta’s experience from TU Delft in providing the support to help researchers achieve these goals. We hope that by doing this we would appeal to both researchers and to support staff in the audience:
- Researchers will get some tangible examples from Laurent’s experience.
- Support staff can see how to best support researchers with making their research more Findable, Accessible, Interoperable and Re-usable (FAIR).
Parts of this post are based on previous Laurent’s notes/talks from talks on Becoming a better scientist with open and reproducible research from May 2019 and Dec 2020.
Who’s here?
Speakers: we are Dr Marta Teperek (Head of Research Data Services at TU Delft Library and Director of 4TU.ResearchData, The Netherlands) and Prof Laurent Gatto (Computational Biology and Bioinformatics Unit, de Duve Institute, UCLouvain, Belgium)
Audience: a week or so before the seminar, we had 158 registered attendees. Out of which 114 are research postgraduate students, 26 are HKUST staff/faculty, and 9 are guest participants (librarians from other HK universities). The break-down of HKUST participants’ school affiliations gives: Science: 48 (32%), Business: 13 (9%), Admin offices (library, research office): 12 (8%), Humanities and Social Sciences: 19 (12%) and Engineering: 59 (39%).
How it all started
From 2010 in Cambridge to 2021 in Hong Kong (virtually).
In 2010 Laurent was doing his postdoc in the Department of Biochemistry at the University of Cambridge. At the same time, Marta was doing her PhD at the Gurdon Institute, also in Cambridge. We were literally next door neighbours, worked on similar types of research (in fact Marta even collaborated with Laurent’s group on some proteomics analysis) and yet we have only met each other properly in 2016 when our shared passion for open and reproducible research practice allowed us to connect in context of the Data Champions initiative. Laurent was then a Data Champion, and Marta part of the Research Data Services at Cambridge.

What is ‘Open’, ‘Reproducible’ and ‘Good’ science?
- Poll: Do you practice open and/or reproducible research?
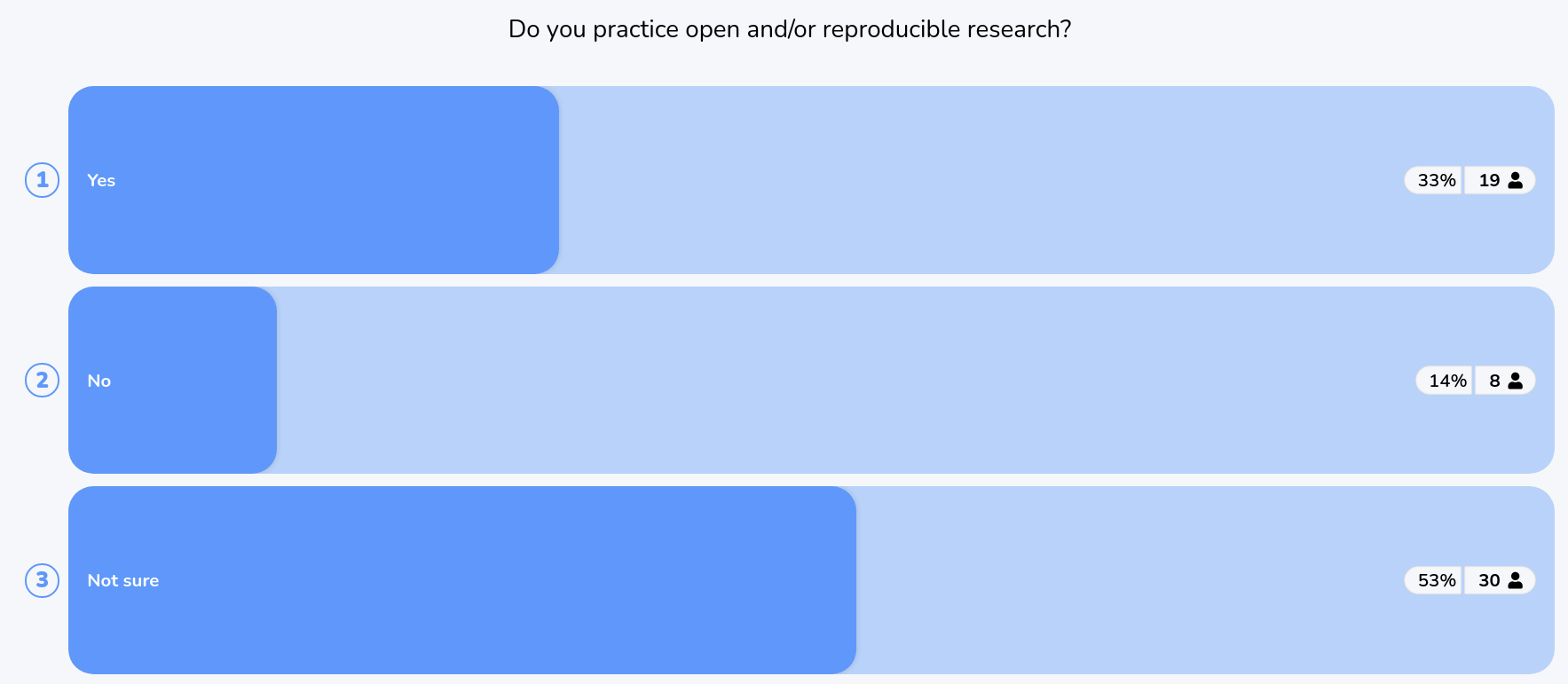
- Wordcloud: Ask for a couple of words describing how participants see open/reproducible research and create a word cloud?

Laurent
We can start with a definition:
Open science/research is the process of transparent dissemination and access to knowledge, that can be applied to various scientific practices: open data, open source, open access, …
and
Reproducible research: there exist several levels, of increasing difficulty, that describe the action of using external data/software/material/informations to attempt to observe the same or comparable results. Formally, we repeat, reproduce, replicate or re-use depending on how much of the original material we have access to.
What I dislike about the previous open science/research definition is that it can give the misleading impression that open research is about collecting badges, and that the more badges you possess, the better an open researcher you are. And reciprocally, not having any badge to display excludes one from being an open researcher. And as soon as people start to believe this, we will stop practicing open research and will start doing stamp collection.
Also, Open science/research can mean different things to different people, in particular when declined along its many technical, administrative, legal and philosophical attributes.
An important word above is excludes: as thriving open researchers, we need to understand that it isn’t only the distance towards better/open research that we have travelled that is relevant, but that the starting point matters a lot. The way somebody practices open research, whether that person has the possibility to implement this or that open (and reproducible) research practice, or whether they can be vocal about it mostly depends on their environment and the support or push back they get.
Embrace open and reproducible research to the extent you want and you can. Seek allies and support around you, but do not feel pressured. It isn’t open or closed. It is certainly not the same open or close for everybody.
So my very first take-home messages are:
Open and reproducible aren’t binary, they are gradients, multidisciplinary and multidimensional.
How to be an open scientist and implement RR:
Let’s be open and understanding of different situations and constraints, including our own.
And also:
Open != reproducible
Open != good (by default)
Reproducible != good (by default)
Open research and reproducible research aren’t the same thing, and one doesn’t imply the other. Even though in our modern understanding of these terms and concepts, they are intimately linked, historically, they are very different. And research being open or reproducible doesn’t make it good (whatever the definition of good).
But open and reproducible research are supported by good data management (the topic of this talk/post) and lead to trust, verification and guarantees:
- Trust in Reporting - result is accurately reported
- Trust in Implementation - analysis code successfully implements chosen methods
- Statistical Trust - data and methods are (still) appropriate
- Scientific Trust - result convincingly supports claim(s) about underlying systems or truths
which are a hallmark of good research.
From Gabriel Becker An Imperfect Guide to Imperfect Reproducibility, May Institute for Computational Proteomics, 2019.
People support
Laurent
Working openly and reproducibly is paramount for my own and my close collaborators/students’ benefit. Hence, it was natural for me, when starting my research group, to center the lab’s activities around the principles of good data management to enable open and reproducible research that you can trust.
This is reflected in the CBIO lab statement:
Open Science and Reproducible Research We are committed to the open, transparent and rigorous practice of scientific enquiry. In particular, we make every possible effort to make our research repeatable, reproducible and replicable, in the hope that it can be re-used and improved upon by as many as possible. Concomitantly, we release all our software and data under open permissible licences. Finally, we will also ensure that our research (such as, but not limited to journals articles, presentations, and book chapters) is published under open access licences to allow everybody to freely read, re-use and mine it.
Marta
To a lot of researchers the effort, but also the skills needed to effectively manage their research data and software might be insurmountable barriers. And the truth is that we should not be expecting researchers to be excellent at everything: doing research, applying for grants, managing people, writing papers, teaching, managing research data and software. Science should be more about teamwork, not about heroic efforts of individuals. And working as a team and bringing different types of expertise together, teams can be much more efficient at answering the big and challenging questions. So researchers need to be supported by skilled professionals.
At TU Delft we have two main groups of colleagues who provide researchers with dedicated support for data and software management:
-
Data stewards - at TU Delft we have one data steward at every faculty. Each faculty specialises in its own area of research and data steward provide expert advice in this research area. They are not only the go to people for researchers who need support with data management, but they also advise the faculties on policies, provide training and raise awareness about data management and reproducible research within the research community.
-
Digital Competence Centre Support team - this team consists of a central pool of data managers and research software engineers. Members of this team provide hands-on support to research groups. They teach researchers skills necessary to make their data and software Findable, Accessible, Interoperable and Reusable (FAIR) by working with them on their data and software. They help researchers create effective data management pipelines, make datasets more interoperable, introduce entire teams to version control for data and code, improve the quality and sustainability of their research software. Researchers apply to receive their support and if such applications are granted (competitive process), team members join their research groups for up to 2 days per week and up to 6 months.
All of these colleagues have research experience and most have a PhD degree.
And dedicated people are also essential to support infrastructure - to be the human side of it. At TU Delft we also make use of 4TU.ResearchData, which is a data and code repository shared between four technical universities in the Netherlands. It provides all the state-of-the-art functionalities, such as DOIs for data, long-term preservation, versioning, Git integration, but what makes the biggest difference to the researchers is the dedicated support of our data curators.
Practice and policy
- Poll: Does your institution have policies in place on data management?
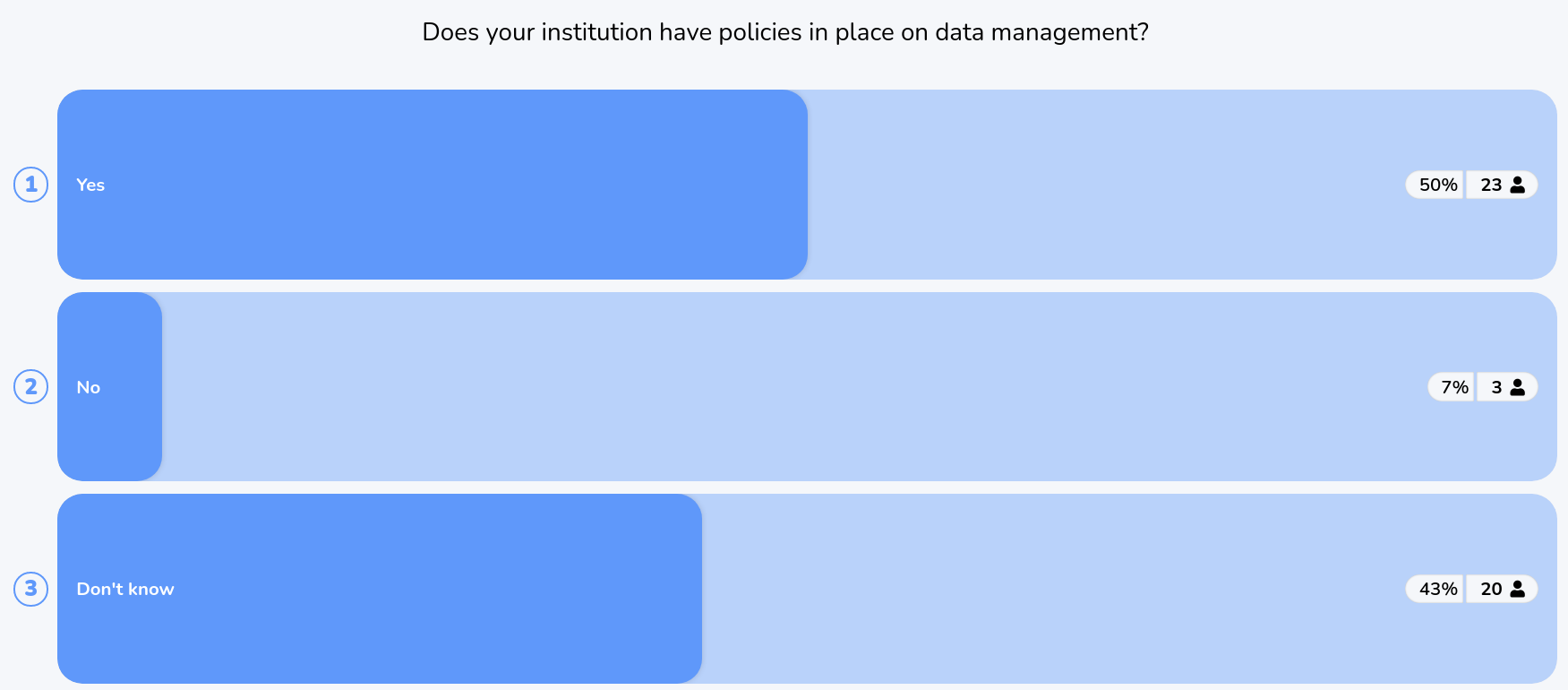
Laurent
Here’s an example of practice from my research:
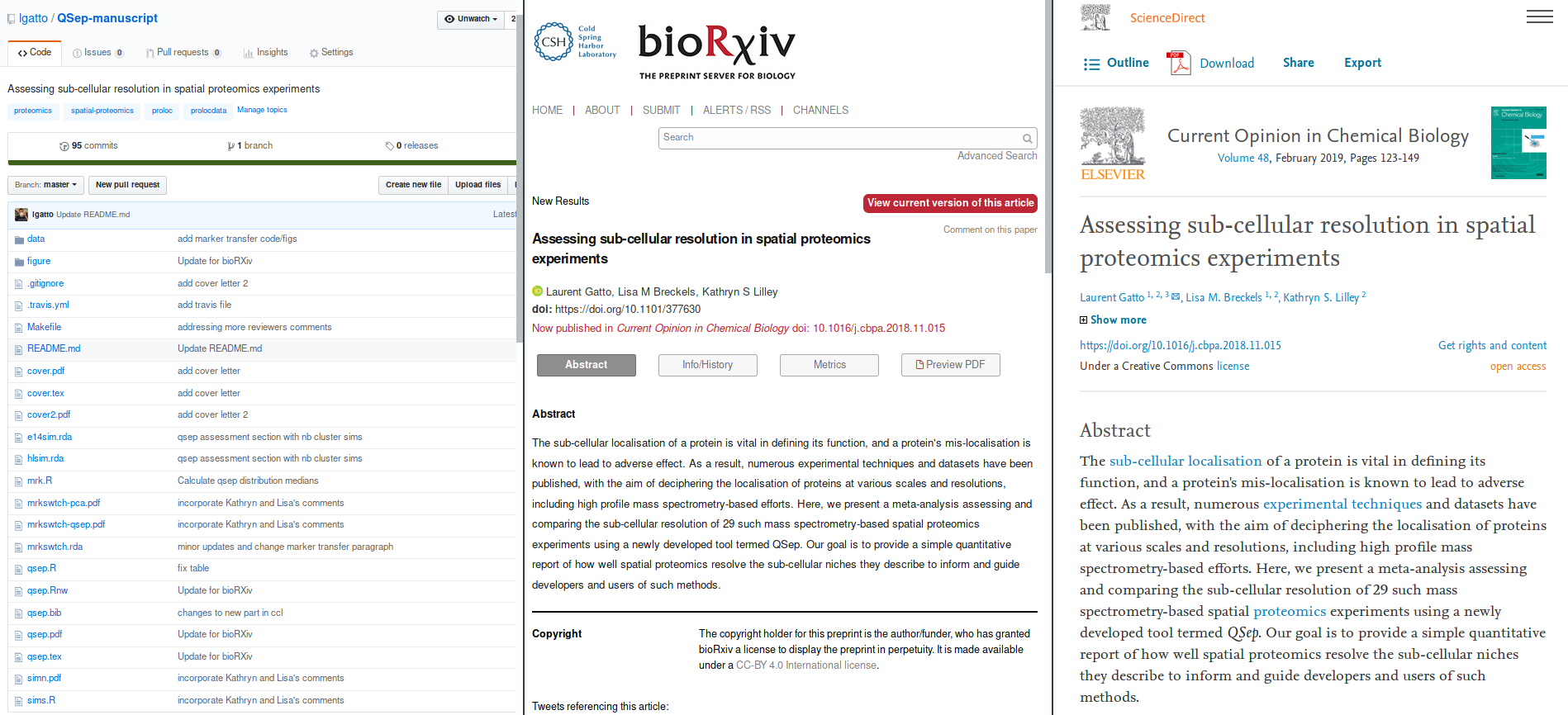
From left to right, we have an example of practice of open and reproducible research:
- A reproducible document, produced with open source software and curated data,
- a preprint and
- a peer reviewer paper.
But one might ask: does it take more time to work reproducibly?
No, it is a matter of relocating time!
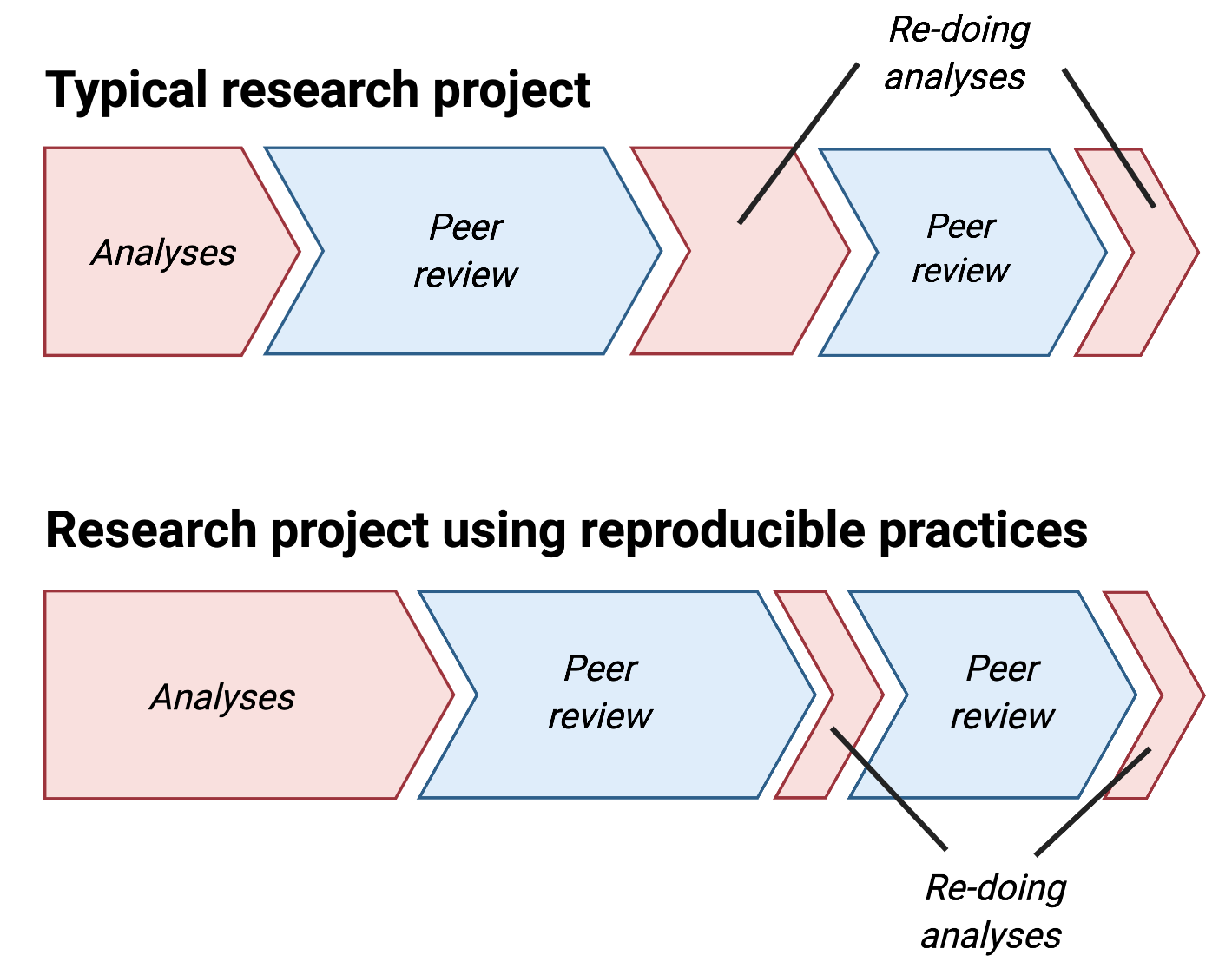
From Five things about open and reproducible science that every early career researcher should know.
From personal experience, I can say that policies aren’t the main motivation to practice good data management. It is important for data management to be an intrinsic motivation, which can (or should) easily be triggered by the desire to produce trusted research.
Local action at a lab’s level and/or at the initiative of one or a few motivated researchers (early career researchers and faculty) is possible, easy and efficient. However, it is extremely difficult to expand outside of one’s direct environment. For this, policies are important.
Marta
If policies are introduced top-down and just for the sake of having them in place (compliance reasons or ways for research institutions to demonstrate they care about the good practice), there is indeed a high risk that they would turn into a box-ticking exercise. Or worse, they turn into meaningless documents with the majority of people they are supposed to apply to, not even aware they exist.
On the other hand, if policies are introduced through consultations with the community and if they go hand-in-hand with practice, they can become powerful tools for driving cultural change more widely, at the institutional level. At TU Delft we have a separate set of policies (!) for research data management and a recently introduced policy and guidelines for research software.
Our data policy consists of a framework policy which sets out the basic roles and responsibilities for everyone at TU Delft: from every researcher, through deans, support staff, and all the way to the rectorate. Faculties developed their own data policies, based on the framework policy, where they provide disciplinary specific interpretations of the framework.
It took years of consultations with all the stakeholders at TU Delft to arrive at a policy text with which everyone was happy with, as well as with concrete roles and responsibilities. Interestingly, researchers were sometimes the main drivers for strict policies. For example, some of the professors were really concerned about PhD students leaving TU Delft with all the data, or leaving messy data behind. Hence, they were very keen on introducing a data management plan as a compulsory deliverable for PhD students during their first year Viva (go/no go assessment) and also to ensure that they upload their data to a repository before graduation.
These two actions are drivers to better data management. Since the introduction of the policy we have seen huge demand for training on data management, but also keep hearing from PhD students who say that they managed to introduce their supervisors and sometimes their entire research teams to better data management practices.
Another example is TU Delft’s Research Software Policy. That’s another policy which took years to develop and implement and one which was driven by a researcher who was fed up with TU Delft’s copyright stance. TU Delft’s official stance on copyright, probably the same as of most research institutions, was largely that TU Delft owns copyright on software produced by TU Delft researchers, and if researchers wished to publish software, they needed to ask TU Delft for a written permission through filing an invention disclosure form. A lot of unnecessary bureaucracy, frustrating for everyone.
Under the new software policy, researchers who wish to publish their research software under open licences, are automatically allowed to do so and TU Delft transfers copyright to them. This not only hugely reduces the administrative burden on everyone, but also promotes open source software practices across the entire institution.
Training
- Poll: have you had any dedicated training on data management and reproducible research?

Laurent
I started as a Carpentries instructor and now apply these lessons and best practices in my university courses (bachelor and masters in biomedical sciences (for example here, here and here) and teaching these in workshops for graduate students and ECR.
Teaching data management, open and reproducible research principles when running a lab is ideal to host students that are well trained in RDM and RR are readily up to speed to start their research.
Marta
I wholeheartedly believe that it is essential that adequate training is available to support researchers in managing their data and software. While researchers should not need to do everything on their own (there is also the need for people support), having a solid background in data management and software management skills is often essential to properly benefit from such support and to make sure it leads to long-term benefits by becoming embedded in the researchers’ workflows and practices.
At TU Delft our Data Managers and Research Software Engineers regularly receive requests for hands-on support. But often for these technical experts to even get started, it is essential to establish a common understanding with the research team about what needs to be done and how to do it best. For this to happen, they need to speak the same language. Solid software and data management skills are essential to do efficient and effective research and to save a lot of time and money.
As nicely articulated in the recent OECD report Building Digital Workforce Capacity and Skills for Data-intensive Science:
Academic libraries (…) are a natural focus for digital skills support and capacity building (…). [They] train others in data and software practices, particularly in relation to foundational skills and data stewardship.(…)…Libraries can be an important resource for universities to increase their digital workforce capacities, provided that the necessary investment is made.
At TU Delft we have developed a shared vision on what kind of data and software management training should be provided to our researchers. The vision was published in 2019. Since then we have been working hard to implement this vision. Feedback we have been receiving on our courses has been really good and emphasised the need for training. However, we have already hit a capacity gap. Our supply for training is unable to meet the demand. So, as the OECD report stated, investment is necessary.
But as Laurent said, the Carpentries are an excellent example of where collaboration between support staff and researchers is essential. To deliver the Carpentries, the Library provides the framework, pays for the membership, organises instructor training and coordinates the organisations. The courses themselves are delivered by a community of instructors, consisting of data stewards and researchers. Software Carpentry workshops are typically discipline-agnostic, but to delivery discipline-specific data carpentries, such as the Genomic Data Carpentry or Data Carpentry for Social Sciences, it is essential to partner with researchers who work on these types of data.
Rewards
- Wordcloud: What would motivate you towards being more open/RR? More citations, better chances of getting hired, …

Laurent
Benefits for your academic career: How open science helps researchers succeed and more examples from the Open as a career boost paragraph:
- Open access articles get more citations.
- Open publications get more media coverage.
- Data availability is associated with citation benefit.
- Openly available software is more likely to be used. (I don’t have any reference for this, and there are of course many couterexamples).
- Benefit from institutional support of open research practices
Networking opportunities (this talk here today)
See also Why Open Research
- Increase your visibility: Build a name for yourself. Share your work and make it more visible.
- Reduce publishing costs: Open publishing can cost the same or less than traditional publishing.
- Take back control: Know your rights. Keep your rights. Decide how your work is used
- Publish where you want: Publish in the journal of your choice and archive an open copy. (See The cost of knowledge boycott of Elsevier).
- Get more funding: Meet funder requirements, and qualify for special funds such as the Wellcome Trust Open Research Fund.
- Get that promotion: Open research is increasingly recognised in promotion and tenure. See also Reproducibility and open science are starting to matter in tenure and promotion July 14th, 2017, Brian Nosek) and the EU’s Evaluation of Research Careers fully acknowledging Open Science Practice defines an Open Science Career Assessment Matrix (OS-CAM).
And of course the Five selfish reasons to work reproducibly!.
Marta
There are also changes happening in the reward and recognition of researchers at institutional, national and international levels. Internationally, DORA has been the agent of change. There seems to be the moment growing recognising that publications and impact factors aren’t suitable indicators of research quality or impact and that publication pressure can have serious adverse effects. More and more organisations want to discourage the use of impact factors in research evaluation. DORA will develop a dashboard tracking hiring and promotion criteria across the institutions. Funders are also taking important steps forward. For example, the Wellcome Trust in the UK has been awarding dedicated funds for Open Research since 2018. NWO, the main Dutch science funder not only has been awarding funding to open science and reproducible research, but also introduced ‘narrative CVs’ for researchers who apply for grants. Institutions also become increasingly pro-active at recognising that change in recognition and rewards is necessary.
But in my opinion the most important changes are the ones done by individuals. Everyone matters, everyone can contribute to making a difference. When I think about the work that Laurent does… he now has two Master students in his lab who got inspired by his practice and wanted to do projects with him. We can all lead by example and should continue doing this.
Here we should also remember that recognition also means recognising the crucial work of support staff, who are often important drivers for Open Science and Reproducible Research practice. The work of data managers, data stewards, research software engineers, community managers, librarians is sometimes not visible, but it is essential and should be recognised as such. Here we would also like to thank the organisers for bringing us all together today and facilitating today’s discussion on open and reproducible research practices.
Community
Community, peer support and meeting great people. Open not only as in sharing, but as inclusive and welcoming. ♥
Laurent
There is
Open Science as in widely disseminated and openly accessible
and
Open Science as in inclusive and welcoming
Citing Cameron Neylon:
The primary value proposition of #openscience is that diverse contributions allow better critique, refinement, and application 3/n
— CⓐmeronNeylon (@CameronNeylon) August 10, 2017
And since 2010, Marta and Laurent still work together :-)
Marta
I fully agree with Laurent about the impact and importance of communities. In many universities there are now Data Champions, Data Ambassadors, Open Science or Open Research Communities… So join one if you have one! And if you don’t have one, no problem. These communities are bottom up. This means you can simply start from meeting for a coffee with a like-minded colleague or two. That’s how Laurent and colleagues have started the OpenConCambridge back then. Entirely bottom-up. You don’t need to wait for someone else to get started. Any opportunity to connect with like-minded individuals sharing your thoughts and curiosity about open science and reproducible working practices is a great opportunity. And who knows, maybe this webinar will be your chance to get started?
And to give you some concrete benefit… The journey that Laurent and I had together started in 2010. Now, in 2021, virtually in Honk-Kong we are still friends and we now we will always support one another and can rely on each other. Also when preparing this seminar.
Credits
Laurent: One of my advice was to make allies. I have been lucky to meet wonderful allies and inspiring friends along the path towards open and reproducible research that works for me. Among these, I would like to highlight Corina Logan, Stephen Eglen, Marta Teperek, Kirstie Whitaker, Chris Hartgenink, Naomie Penfold, Yvonne Nobis.
Marta: Would like to give credit to numerous colleagues from TU Delft and beyond who were the driving force behind all the work described in this post, and in particular: Alastair Dunning, Anke Versteeg, Connie Clare, Data Stewards (Diana Popa, Esther Plomp, Heather Andrews, Jasper van Dijk, Jeff Love, Kees den Heijer, Nicolas Dintzner, Robert Eggermont, Santosh Ilamparuthi, Shalini Kurapati, Yan Wang, Yasemin Turkyilmaz-van der Velden), Digital Competence Centre Support Team (Amir Fard, Ashley Cryan, Jose Urra, Julie Beardsell, Manuel Garcia, Mark Schenk, Maurits Kok, Meta Keijzer-de Ruijter, Niket Agrawal, Susan Branchett), Eirini Zormpa, Emmy Tsang, Irene Haslinger, Karel Luyben, Maria Cruz, Paula Martinez Lavanchy.
